Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

[ad_1]
Whereas not instantly apparent, all of us expertise the world in 4 dimensions (4D). For instance, when strolling or driving down the road we observe a stream of visible inputs, snapshots of the 3D world, which, when taken collectively in time, creates a 4D visible enter. At present’s autonomous automobiles and robots are capable of seize a lot of this info by numerous onboard sensing mechanisms, akin to LiDAR and cameras.
LiDAR is a ubiquitous sensor that makes use of gentle pulses to reliably measure the 3D coordinates of objects in a scene, nevertheless, it is usually sparse and has a restricted vary — the farther one is from a sensor, the less factors will probably be returned. Because of this far-away objects would possibly solely get a handful of factors, or none in any respect, and won’t be seen by LiDAR alone. On the similar time, pictures from the onboard digital camera, which is a dense enter, are extremely helpful for semantic understanding, akin to detecting and segmenting objects. With excessive decision, cameras may be very efficient at detecting objects far-off, however are much less correct in measuring the gap.
Autonomous automobiles accumulate knowledge from each LiDAR and onboard digital camera sensors. Every sensor measurement is recorded at common time intervals, offering an correct illustration of the 4D world. Nonetheless, only a few analysis algorithms use each of those together, particularly when taken “in time”, i.e., as a temporally ordered sequence of knowledge, largely resulting from two main challenges. When utilizing each sensing modalities concurrently, 1) it’s tough to take care of computational effectivity, and a couple of) pairing the data from one sensor to a different provides additional complexity since there’s not all the time a direct correspondence between LiDAR factors and onboard digital camera RGB picture inputs.
In “4D-Web for Discovered Multi-Modal Alignment”, revealed at ICCV 2021, we current a neural community that may course of 4D knowledge, which we name 4D-Web. That is the primary try and successfully mix each forms of sensors, 3D LiDAR level clouds and onboard digital camera RGB pictures, when each are in time. We additionally introduce a dynamic connection studying methodology, which includes 4D info from a scene by performing connection studying throughout each characteristic representations. Lastly, we display that 4D-Web is best ready to make use of movement cues and dense picture info to detect distant objects whereas sustaining computational effectivity.
4D-Web
In our state of affairs, we use 4D inputs (3D level clouds and onboard digital camera picture knowledge in time) to resolve a very talked-about visible understanding process, the 3D field detection of objects. We research the query of how one can mix the 2 sensing modalities, which come from completely different domains and have options that don’t essentially match — i.e., sparse LiDAR inputs span the 3D area and dense digital camera pictures solely produce 2D projections of a scene. The precise correspondence between their respective options is unknown, so we search to be taught the connections between these two sensor inputs and their characteristic representations. We think about neural community representations the place every of the characteristic layers may be mixed with different potential layers from different sensor inputs, as proven under.
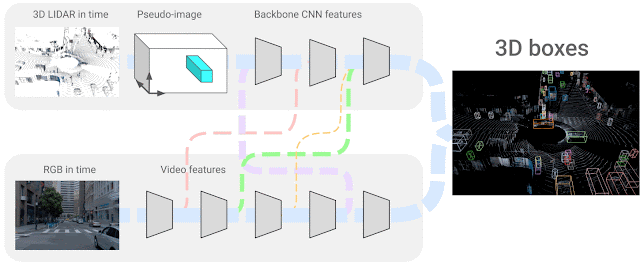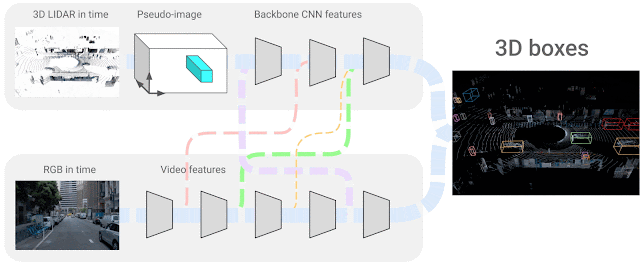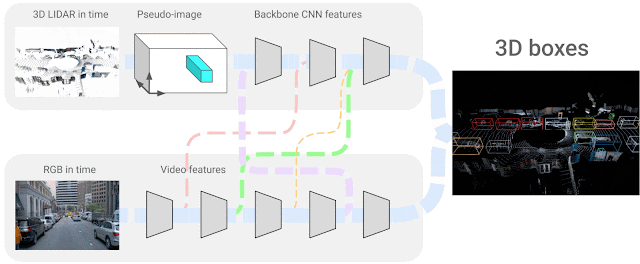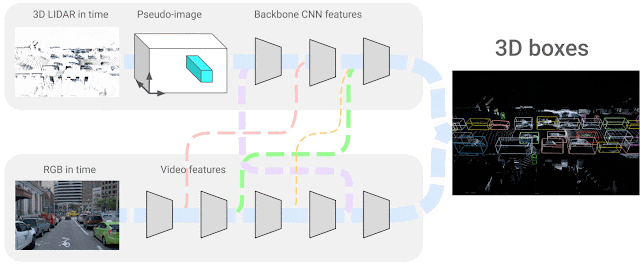 |
| 4D-Web successfully combines 3D LiDAR level clouds in time with RGB pictures, additionally streamed in time as video, studying the connections between completely different sensors and their characteristic representations. |
Dynamic Connection Studying Throughout Sensing Modalities
We use a lightweight neural structure search to be taught the connections between each forms of sensor inputs and their characteristic representations, to acquire probably the most correct 3D field detection. Within the autonomous driving area it’s particularly essential to reliably detect objects at extremely variable distances, with trendy LiDAR sensors reaching a number of tons of of meters in vary. This suggests that extra distant objects will seem smaller within the pictures and probably the most beneficial options for detecting them will probably be in earlier layers of the community, which higher seize fine-scale options, versus close-by objects represented by later layers. Based mostly on this remark, we modify the connections to be dynamic and choose amongst options from all layers utilizing self-attention mechanisms. We apply a learnable linear layer, which is ready to apply attention-weighting to all different layer weights and be taught the most effective mixture for the duty at hand.
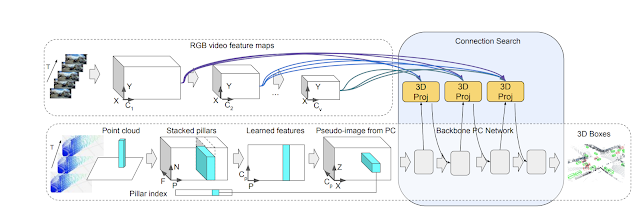 |
| Connection studying strategy schematic, the place connections between options from the 3D level cloud inputs are mixed with the options from the RGB digital camera video inputs. Every connection learns the weighting for the corresponding inputs. |
Outcomes
We consider our outcomes towards state-of-the-art approaches on the Waymo Open Dataset benchmark, for which earlier fashions have solely leveraged 3D level clouds in time or a mixture of a single level cloud and digital camera picture knowledge. 4D-Web makes use of each sensor inputs effectively, processing 32 level clouds in time and 16 RGB frames inside 164 milliseconds, and performs effectively in comparison with different strategies. Compared, the subsequent greatest strategy is much less environment friendly and correct as a result of its neural internet computation takes 300 milliseconds, and makes use of fewer sensor inputs than 4D-Web.
 |
 |
| Outcomes on a 3D scene. Prime: 3D containers, comparable to detected automobiles, are proven in several colours; dotted line containers are for objects that had been missed. Backside: The containers are proven within the corresponding digital camera pictures for visualization functions. |
Detecting Far-Away Objects
One other good thing about 4D-Web is that it takes benefit of each the excessive decision supplied by RGB, which might precisely detect objects on the picture aircraft, and the correct depth that the purpose cloud knowledge gives. Because of this, objects at a larger distance that had been beforehand missed by level cloud-only approaches may be detected by a 4D-Web. That is as a result of fusion of digital camera knowledge, which is ready to detect distant objects, and effectively propagate this info to the 3D a part of the community to supply correct detections.
Is Information in Time Useful?
To grasp the worth of the 4D-Web, we carry out a collection of ablation research. We discover that substantial enhancements in detection accuracy are obtained if at the least one of many sensor inputs is streamed in time. Contemplating each sensor inputs in time gives the biggest enhancements in efficiency.
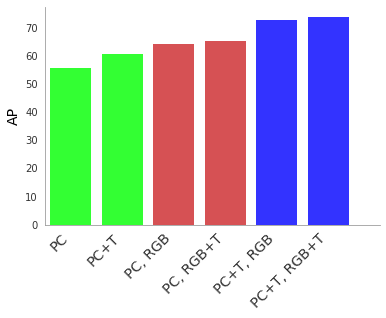 |
| 4D-Web efficiency for 3D object detection measured in common precision (AP) when utilizing level clouds (PC), Level Clouds in Time (PC + T), RGB picture inputs (RGB) and RGB pictures in Time (RGB + T). Combining each sensor inputs in time is greatest (rightmost columns in blue) in comparison with the left-most columns (inexperienced) which use a PC with out RGB inputs. All joint strategies use our 4D-Web multi-modal studying. |
Multi-stream 4D-Web
For the reason that 4D-Web dynamic connection studying mechanism is normal, we aren’t restricted to solely combining some extent cloud stream with an RGB video stream. In truth, we discover that it is rather cost-effective to offer a big decision single-image stream, and a low-resolution video stream together with 3D level cloud stream inputs. Beneath, we display examples of a four-stream structure, which performs higher than the two-stream one with level clouds in time and pictures in time.
Dynamic connection studying selects particular characteristic inputs to attach collectively. With a number of enter streams, 4D-Web has to be taught connections between a number of goal characteristic representations, which is simple because the algorithm doesn’t change and easily selects particular options from the union of inputs. That is an extremely lightweight course of that makes use of a differentiable structure search, which might uncover new wiring throughout the mannequin structure itself and thus successfully discover new 4D-Web fashions.
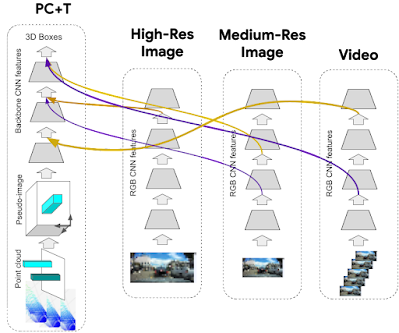 |
| Instance multi-stream 4D-Web which consists of a stream of 3D level clouds in time (PC+T), and a number of picture streams: a high-resolution single picture stream, a medium-resolution single picture stream and a video stream (of even decrease decision) pictures. |
Abstract
Whereas deep studying has made great advances in real-life functions, the analysis group is simply starting to discover studying from a number of sensing modalities. We current 4D-Web which learns mix 3D level clouds in time and RGB digital camera pictures in time, for the favored utility of 3D object detection in autonomous driving. We display that 4D-Web is an efficient strategy for detecting objects, particularly at distant ranges. We hope this work will present researchers with a beneficial useful resource for future 4D knowledge analysis.
Acknowledgements
This work is finished by AJ Piergiovanni, Vincent Casser, Michael Ryoo and Anelia Angelova. We thank our collaborators, Vincent Vanhoucke, Dragomir Anguelov and our colleagues at Waymo and Robotics at Google for his or her assist and discussions. We additionally thank Tom Small for the graphics animation.
[ad_2]