Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

[ad_1]
That is the fifth in a sequence of posts. We’re excited to share dozens of recent options to automate your schema conversion; protect your funding in present scripts, reviews, and functions; speed up question efficiency; and doubtlessly simplify your migrations from legacy information warehouses to Amazon Redshift.
Amazon Redshift is the main cloud information warehouse. No different information warehouse makes it as simple to realize new insights out of your information. With Amazon Redshift, you possibly can question exabytes of information throughout your information warehouse, operational information shops, and information lake utilizing normal SQL. You can too combine different AWS companies comparable to Amazon EMR, Amazon Athena, Amazon SageMaker, AWS Glue, AWS Lake Formation, and Amazon Kinesis to make use of all of the analytic capabilities within the AWS Cloud.
Till now, migrating an information warehouse to AWS has been a fancy enterprise, involving a major quantity of guide effort. You must manually remediate syntax variations, inject code to exchange proprietary options, and manually tune the efficiency of queries and reviews on the brand new platform.
Legacy workloads could depend on non-ANSI, proprietary options that aren’t immediately supported by fashionable databases like Amazon Redshift. For instance, many Teradata functions use SET tables, which implement full row uniqueness—there can’t be two rows in a desk which can be equivalent in all of their attribute values.
When you’re an Amazon Redshift person, you could need to implement SET semantics however can’t depend on a local database function. You should use the design patterns on this publish to emulate SET semantics in your SQL code. Alternatively, in case you’re migrating a workload to Amazon Redshift, you should utilize the AWS Schema Conversion Instrument (AWS SCT) to routinely apply the design patterns as a part of your code conversion.
On this publish, we describe the SQL design patterns and analyze their efficiency, and present how AWS SCT can automate this as a part of your information warehouse migration. Let’s begin by understanding how SET tables behave in Teradata.
At first look, a SET desk could appear just like a desk that has a major key outlined throughout all of its columns. Nevertheless, there are some essential semantic variations from conventional major keys. Take into account the next desk definition in Teradata:
We populate the desk with 4 rows of information, as follows:
Discover that we didn’t outline a UNIQUE PRIMARY INDEX (just like a major key) on the desk. Now, after we attempt to insert a brand new row into the desk that may be a duplicate of an present row, the insert fails:
Equally, if we attempt to replace an present row in order that it turns into a replica of one other row, the replace fails:
In different phrases, easy INSERT-VALUE and UPDATE statements fail in the event that they introduce duplicate rows right into a Teradata SET desk.
There’s a notable exception to this rule. Take into account the next staging desk, which has the identical attributes because the goal desk:
The staging desk is a MULTISET desk and accepts duplicate rows. We populate three rows into the staging desk. The primary row is a replica of a row within the goal desk. The second and third rows are duplicates of one another, however don’t duplicate any of the goal rows.
Now we efficiently insert the staging information into the goal desk (which is a SET desk):
If we look at the goal desk, we will see {that a} single row for (2022-01-05, 500) has been inserted, and the duplicate row for (2022-01-01, 100) has been discarded. Primarily, Teradata silently discards any duplicate rows when it performs an INSERT-SELECT assertion. This consists of duplicates which can be within the staging desk and duplicates which can be shared between the staging and goal tables.
Primarily, SET tables behave in a different way relying on the kind of operation being run. An INSERT-VALUE or UPDATE operation suffers a failure if it introduces a replica row into the goal. An INSERT-SELECT operation doesn’t endure a failure if the staging desk accommodates a replica row, or a replica row is shared between the staging and desk tables.
On this publish, we don’t go into element on the way to convert INSERT-VALUE or UPDATE statements. These statements sometimes contain one or just a few rows and are much less impactful when it comes to efficiency than INSERT-SELECT statements. For INSERT-VALUE or UPDATE statements, you possibly can materialize the row (or rows) being created, and be a part of that set to the goal desk to examine for duplicates.
In the remainder of this publish, we analyze INSERT-SELECT statements rigorously. Prospects have advised us that INSERT-SELECT operations can comprise as much as 78% of the INSERT workload in opposition to SET tables. We’re involved with statements with the next type:
The schema of the staging desk is equivalent to the goal desk on a column-by-column foundation. As we talked about earlier, a replica row can seem in two totally different circumstances:
As a result of Amazon Redshift helps multiset desk semantics, it’s potential that the staging desk accommodates duplicates (the primary circumstance we listed). Due to this fact, any automation should deal with each instances, as a result of both can introduce a replica into an Amazon Redshift desk.
Based mostly on this evaluation, we carried out the next algorithms:
We additionally thought of different algorithms, however we don’t advocate that you simply use them. For instance, you possibly can carry out a GROUP BY to remove duplicates within the staging desk, however this step is pointless in case you use the MINUS operator. You can too carry out a left (or proper) outer be a part of to search out shared duplicates between the staging and goal tables, however then further logic is required to account for NULL = NULL circumstances.
We examined the MINUS and MINUS-MIN-MAX algorithms on Amazon Redshift. We ran the algorithms on two Amazon Redshift clusters. The primary configuration consisted of 6 x ra3.4xlarge nodes. The second consisted of 12 x ra3.4xlarge nodes. Every node contained 12 CPU and 96 GB of reminiscence.
We created the stage and goal tables with equivalent type and distribution keys to attenuate information motion. We loaded the identical goal dataset into each clusters. The goal dataset consisted of 1.1 billion rows of information. We then created staging datasets that ranged from 20 million to 200 million rows, in 20 million row increments.
The next graph reveals our outcomes.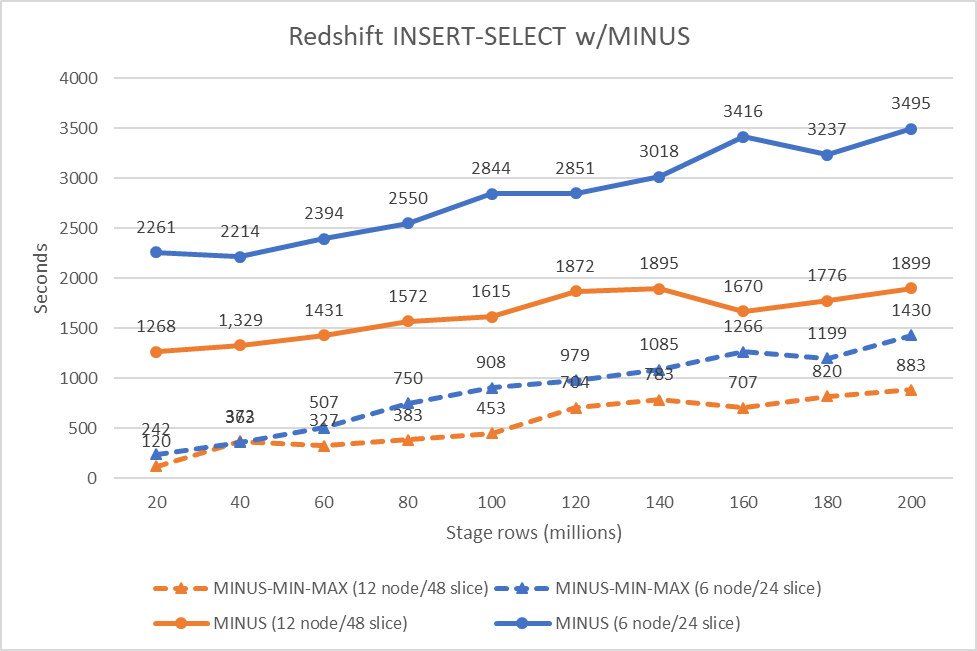
The check information was artificially generated and a few skew was current within the distribution key values. That is manifested within the small deviations from linearity within the efficiency.
Nevertheless, you possibly can observe the efficiency improve that’s afforded the MINUS-MIN-MAX algorithm over the fundamental MINUS algorithm (evaluating orange strains or blue strains to themselves). When you’re implementing SET tables in Amazon Redshift, we advocate utilizing MINUS-MIN-MAX as a result of this algorithm offers a cheerful convergence of straightforward, readable code and good efficiency.
All Amazon Redshift tables permit duplicate rows, i.e., they’re MULTISET tables by default. If you’re changing a Teradata workload to run on Amazon Redshift, you’ll have to implement SET semantics outdoors of the database.
We’re comfortable to share that AWS SCT will routinely convert your SQL code that operates in opposition to SET tables. AWS SCT will rewrite INSERT-SELECT that load SET tables to include the rewrite patterns we described above.
Let’s see how this works. Suppose you might have the next goal desk definition in Teradata:
The stage desk is equivalent to the goal desk, besides that it’s created as a MULTISET desk in Teradata.
Subsequent, we create a process to load the very fact desk from the stage desk. The process accommodates a single INSERT-SELECT assertion:
Now we use AWS SCT to transform the Teradata saved process to Amazon Redshift. First, choose the saved process within the supply database tree, then right-click and select Convert schema.

AWS SCT converts the saved process (and embedded INSERT-SELECT) utilizing the MINUS-MIN-MAX rewrite sample.

And that’s it! Presently, AWS SCT solely performs rewrite for INSERT-SELECT as a result of these statements are closely utilized by ETL workloads and have essentially the most affect on efficiency. Though the instance we used was embedded in a saved process, you can even use AWS SCT to transform the identical statements in the event that they’re in BTEQ scripts, macros, or software packages. Obtain the newest model of AWS SCT and provides it a attempt!
On this publish, we confirmed the way to implement SET desk semantics in Amazon Redshift. You should use the described design patterns to develop new functions that require SET semantics. Or, in case you’re changing an present Teradata workload, you should utilize AWS SCT to routinely convert your INSERT-SELECT statements in order that they protect the SET desk semantics.
We’ll be again quickly with the following installment on this sequence. Examine again for extra data on automating your migrations from Teradata to Amazon Redshift. Within the meantime, you possibly can study extra about Amazon Redshift and AWS SCT. Completely happy migrating!
 Michael Soo is a Principal Database Engineer with the AWS Database Migration Service staff. He builds services that assist prospects migrate their database workloads to the AWS cloud.
Michael Soo is a Principal Database Engineer with the AWS Database Migration Service staff. He builds services that assist prospects migrate their database workloads to the AWS cloud.
 Po Hong, PhD, is a Principal Information Architect of the Trendy Information Structure International Specialty Follow (GSP), AWS Skilled Providers. He’s keen about serving to prospects to undertake revolutionary options and migrate from giant scale MPP information warehouses to the AWS fashionable information structure.
Po Hong, PhD, is a Principal Information Architect of the Trendy Information Structure International Specialty Follow (GSP), AWS Skilled Providers. He’s keen about serving to prospects to undertake revolutionary options and migrate from giant scale MPP information warehouses to the AWS fashionable information structure.
[ad_2]