Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

[ad_1]
That is the ultimate installment in a three-part sequence on Twitter cluster analyses utilizing R and Gephi. Half one analyzed heated on-line dialogue about famed Argentine footballer Lionel Messi; half two deepened the evaluation to raised determine principal actors and perceive matter unfold.
Politics are polarizing. After we discover attention-grabbing communities with drastically completely different opinions, Twitter messages generated from inside these camps are inclined to densely cluster round two teams of customers, with a slight connection between them. Any such grouping and relationship is known as homophily: the tendency to work together with these much like us.
Within the earlier article on this sequence, we centered on computational strategies based mostly on Twitter information units and had been capable of generate informative visualizations via Gephi. Now we need to use cluster evaluation to grasp the conclusions we will draw from these strategies and determine which social information features are most informative.
We’ll change the sort of information we analyze to focus on this clustering, downloading United States’ political information from Could 10, 2020, via Could 20, 2020. We’ll use the identical Twitter information obtain course of we used within the first article on this sequence, altering the obtain standards to the then-president’s title relatively than “Messi.”
The next determine depicts the interplay graph of the political dialogue; as we did within the first article, we plotted this information with Gephi utilizing the ForceAtlas2 format and coloured by the communities as detected by Louvain.
Let’s dive deeper into the accessible information.
As we’ve mentioned all through this sequence, we will characterize clusters by their authorities, however Twitter offers us much more information that we will parse. For instance, the person’s description subject, the place Twitter customers can present a quick autobiography. Utilizing a phrase cloud, we will uncover how customers describe themselves. This code generates two phrase clouds based mostly on the phrase frequency discovered throughout the information in every cluster’s descriptions and highlights how individuals’s self-descriptions are informative in an mixture approach:
# Load crucial libraries
library(rtweet)
library(igraph)
library(tidyverse)
library(wordcloud)
library(tidyverse)
library(NLP)
library("tm")
library(RColorBrewer)
# First, determine the communities via Louvain
my.com.quick = cluster_louvain(as.undirected(simplify(internet)),decision=0.4)
# Subsequent, get the customers that conform to the 2 largest clusters
largestCommunities <- order(sizes(my.com.quick), lowering=TRUE)[1:4]
community1 <- names(which(membership(my.com.quick) == largestCommunities[1]))
community2 <- names(which(membership(my.com.quick) == largestCommunities[2]))
# Now, cut up the tweets’ information frames by their communities
# (i.e., 'republicans' and 'democrats')
republicans = tweets.df[which(tweets.df$screen_name %in% community1),]
democrats = tweets.df[which(tweets.df$screen_name %in% community2),]
# Subsequent, provided that we've got one row per tweet and we need to analyze customers,
# let’s hold just one row by person
accounts_r = republicans[!duplicated(republicans[,c('screen_name')]),]
accounts_d = democrats[!duplicated(democrats[,c('screen_name')]),]
# Lastly, plot the phrase clouds of the person’s descriptions by cluster
## Generate the Republican phrase cloud
## First, convert descriptions to tm corpus
corpus <- Corpus(VectorSource(distinctive(accounts_r$description)))
### Take away English cease phrases
corpus <- tm_map(corpus, removeWords, stopwords("en"))
### Take away numbers as a result of they don't seem to be significant at this step
corpus <- tm_map(corpus, removeNumbers)
### Plot the phrase cloud displaying a most of 30 phrases
### Additionally, filter out phrases that seem solely as soon as
pal <- brewer.pal(8, "Dark2")
wordcloud(corpus, min.freq=2, max.phrases = 30, random.order = TRUE, col = pal)
## Generate the Democratic phrase cloud
corpus <- Corpus(VectorSource(distinctive(accounts_d$description)))
corpus <- tm_map(corpus, removeWords, stopwords("en"))
pal <- brewer.pal(8, "Dark2")
wordcloud(corpus, min.freq=2, max.phrases = 30, random.order = TRUE, col = pal)
Information from earlier US elections reveals that voters are extremely segregated by geographical area. Let’s deepen our identification evaluation and give attention to one other subject: place_name, the sector the place customers can present the place they reside. This R code generates phrase clouds based mostly on this subject:
# Convert place names to tm corpus corpus <- Corpus(VectorSource(accounts_d[!is.na(accounts_d$place_name),]$place_name))
# Take away English cease phrases
corpus <- tm_map(corpus, removeWords, stopwords("en"))
# Take away numbers
corpus <- tm_map(corpus, removeNumbers)
# Plot
pal <- brewer.pal(8, "Dark2")
wordcloud(corpus, min.freq=2, max.phrases = 30, random.order = TRUE, col = pal)
## Do the identical for accounts_r
The names of some locations could seem in each phrase clouds as a result of voters in each events reside in most places. However some states, like Texas, Colorado, Oklahoma, and Indiana, strongly signify the Republican social gathering whereas some cities, like New York, San Francisco, and Philadelphia, strongly correlate with the Democratic social gathering.
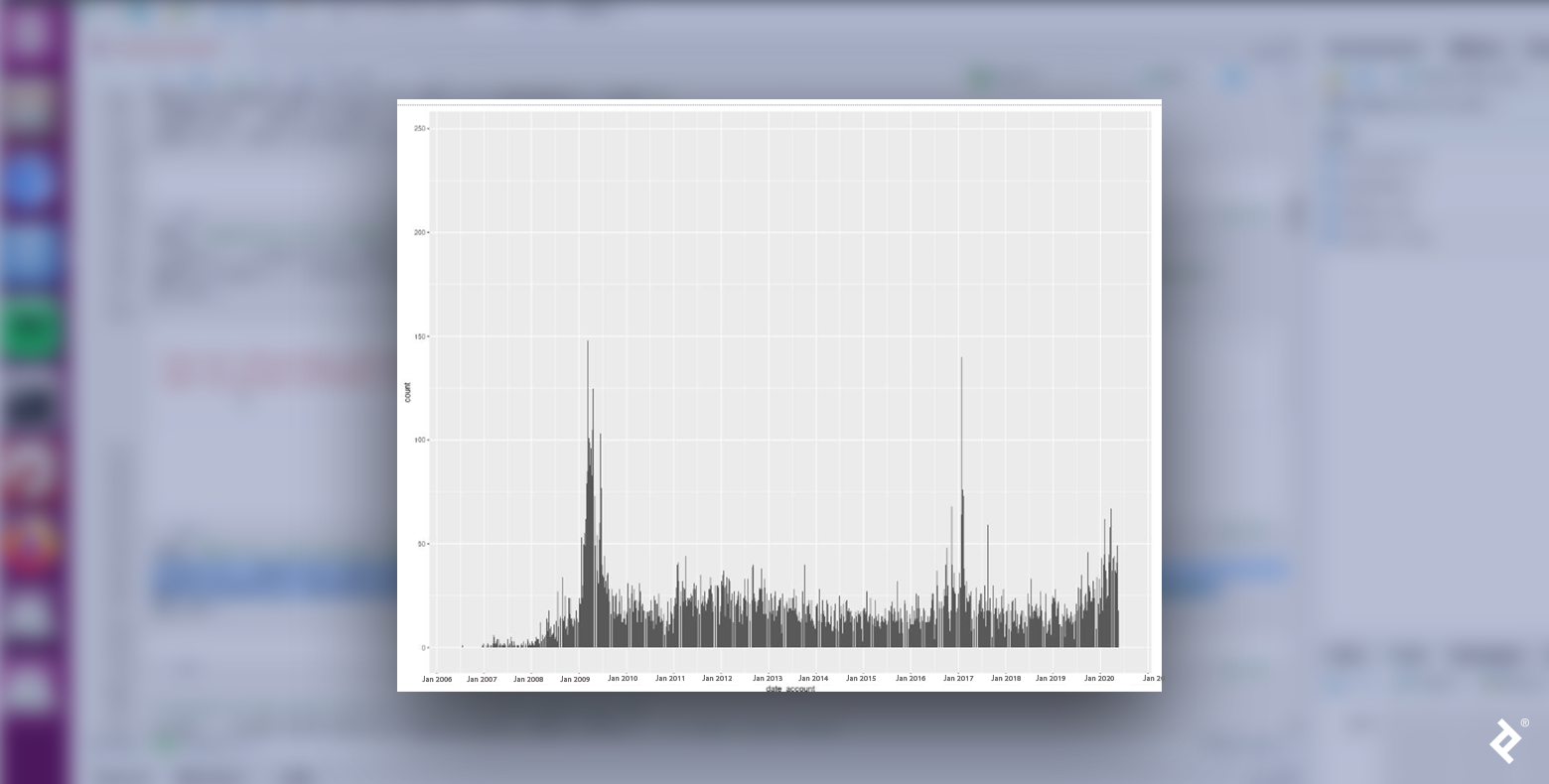
Let’s discover one other side of the info, specializing in person habits and analyzing the distribution of when accounts inside every cluster had been created. If there is no such thing as a correlation between the creation date and the cluster, we’ll see a uniform distribution of customers for every day.
Let’s plot a histogram of the distribution:
# First we have to format the account date subject to be successfully learn as Date
## Word that we're utilizing the accounts_r and accounts_d information body, it is because we need to give attention to distinctive customers and don’t distort the plot by the variety of tweets that every person has submitted
accounts_r$date_account <- as.Date(format(as.POSIXct(accounts_r$account_created_at,format="%Y-%m-%d %H:%M:%S"),format="%Y-%m-%d"))
# Now we plot the histogram
ggplot(accounts_r, aes(date_account)) + geom_histogram(stat="depend")+scale_x_date(date_breaks = "1 12 months", date_labels = "%b %Y")
## Do the identical for accounts_d
We see that Republican and Democratic customers should not distributed uniformly. In each instances, the variety of new person accounts peaked in January 2009 and January 2017, each months when inaugurations occurred following presidential elections within the Novembers of the earlier years. Might or not it’s that the proximity to these occasions generates a rise in political dedication? That may make sense, provided that we’re analyzing political tweets.
Additionally attention-grabbing to notice: The largest peak throughout the Republican information happens after the center of 2019, reaching its highest worth in early 2020. Might this transformation in habits be associated to digital habits introduced on by the pandemic?
The information for the Democrats additionally had a spike throughout this era however with a decrease worth. Possibly Republican supporters exhibited the next peak as a result of that they had stronger opinions about COVID lockdowns? We’d must rely extra on political data, theories, and findings to develop higher hypotheses, however regardless, there are attention-grabbing information tendencies we will analyze from a political perspective.
One other strategy to examine behaviors is to research how customers retweet and reply. When customers retweet, they unfold a message; nevertheless, after they reply, they contribute to a selected dialog or debate. Sometimes, the variety of replies correlates to a tweet’s diploma of divisiveness, unpopularity, or controversy; a person who favorites a tweet signifies settlement with the sentiment. Let’s look at the ratio measure between the favorites and replies of a tweet.
Based mostly on homophily, we might anticipate customers to retweet customers from the identical neighborhood. We will confirm this with R:
# Get customers who've been retweeted by each side
rt_d = democrats[which(!is.na(democrats$retweet_screen_name)),]
rt_r = republicans[which(!is.na(republicans$retweet_screen_name)),]
# Retweets from democrats to republicans
rt_d_unique = rt_d[!duplicated(rt_d[,c('retweet_screen_name')]),]
rt_dem_to_rep = dim(rt_d_unique[which(rt_d_unique$retweet_screen_name %in% unique(republicans$screen_name)),])[1]/dim(rt_d_unique)[1]
# Retweets from democrats to democrats
rt_dem_to_dem = dim(rt_d_unique[which(rt_d_unique$retweet_screen_name %in% unique(democrats$screen_name)),])[1]/dim(rt_d_unique)[1]
# The rest
relaxation = 1 - rt_dem_to_dem - rt_dem_to_rep
# Create a dataframe to make the plot
information <- information.body(
class=c( "Democrats","Republicans","Others"),
depend=c(spherical(rt_dem_to_dem*100,1),spherical(rt_dem_to_rep*100,1),spherical(relaxation*100,1))
)
# Compute percentages
information$fraction <- information$depend / sum(information$depend)
# Compute the cumulative percentages (prime of every rectangle)
information$ymax <- cumsum(information$fraction)
# Compute the underside of every rectangle
information$ymin <- c(0, head(information$ymax, n=-1))
# Compute label place
information$labelPosition <- (information$ymax + information$ymin) / 2
# Compute a great label
information$label <- paste0(information$class, "n ", information$depend)
# Make the plot
ggplot(information, aes(ymax=ymax, ymin=ymin, xmax=4, xmin=3, fill=c('crimson','blue','inexperienced'))) +
geom_rect() +
geom_text( x=1, aes(y=labelPosition, label=label, shade=c('crimson','blue','inexperienced')), measurement=6) + # x right here controls label place (interior / outer)
coord_polar(theta="y") +
xlim(c(-1, 4)) +
theme_void() +
theme(legend.place = "none")
# Do the identical for rt_r
As anticipated, Republicans are inclined to retweet different Republicans and the identical is true for Democrats. Let’s see how social gathering affiliation applies to tweet replies.
A really completely different sample emerges right here. Whereas customers are inclined to reply extra usually to the tweets of people that share their social gathering affiliation, they’re nonetheless more likely to retweet them. Additionally, it seems that individuals who don’t fall throughout the two principal clusters are inclined to want to answer.
Through the use of the subject modeling approach specified by half two of this sequence, we will predict what sort of conversations customers will select to have interaction in with individuals of their identical cluster and with individuals of the alternative cluster.
The next desk particulars the 2 most essential subjects mentioned in every kind of interplay:
| Democrats to Democrats | Democrats to Republicans | Republicans to Democrats | Republicans to Republicans | ||||
| Matter 1 | Matter 2 | Matter 1 | Matter 2 | Matter 1 | Matter 2 | Matter 1 | Matter 2 |
| faux | individuals | trump | individuals | information | biden | individuals | china |
| putin | covid | information | trump | faux | obama | cash | information |
| election | virus | faux | useless | cnn | obamagate | nation | individuals |
| cash | taking | lies | individuals | learn | joe | open | media |
| trump | useless | fox | deaths | fake_news | proof | again | faux |
It seems that faux information was a scorching matter when customers in our information set replied. No matter a person’s social gathering affiliation, after they replied to individuals from the opposite social gathering, they talked about information channels sometimes favored by individuals of their specific social gathering. Secondly, when Democrats replied to different Democrats, they tended to speak about Putin, faux elections, and COVID, whereas Republicans centered on stopping the lockdown and faux information from China.
Polarization is a typical sample in social media, taking place everywhere in the world, not simply within the US. We now have seen how we will analyze neighborhood identification and habits in a polarized situation. With these instruments, anybody can reproduce cluster evaluation on a knowledge set of their curiosity to see what patterns emerge. The patterns and outcomes from these analyses can each educate and assist generate additional exploration.
[ad_2]