Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

[ad_1]
Graph Neural Networks (GNNs) are highly effective instruments for leveraging graph-structured information in machine studying. Graphs are versatile information buildings that may mannequin many various sorts of relationships and have been utilized in various purposes like visitors prediction, rumor and faux information detection, modeling illness unfold, and understanding why molecules odor.
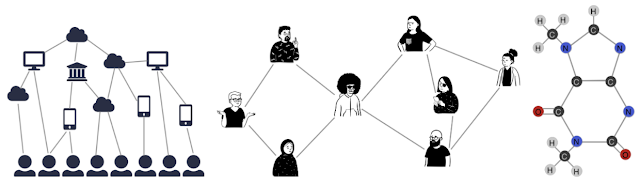 |
| Graphs can mannequin the relationships between many various kinds of information, together with net pages (left), social connections (heart), or molecules (proper). |
As is normal in machine studying (ML), GNNs assume that coaching samples are chosen uniformly at random (i.e., are an impartial and identically distributed or “IID” pattern). That is simple to do with normal educational datasets, that are particularly created for analysis evaluation and subsequently have each node already labeled. Nevertheless, in lots of actual world situations, information comes with out labels, and labeling information may be an onerous course of involving expert human raters, which makes it tough to label all nodes. As well as, biased coaching information is a standard situation as a result of the act of choosing nodes for labeling is normally not IID. For instance, typically mounted heuristics are used to pick out a subset of knowledge (which shares some traits) for labeling, and different occasions, human analysts individually select information objects for labeling utilizing complicated area data.
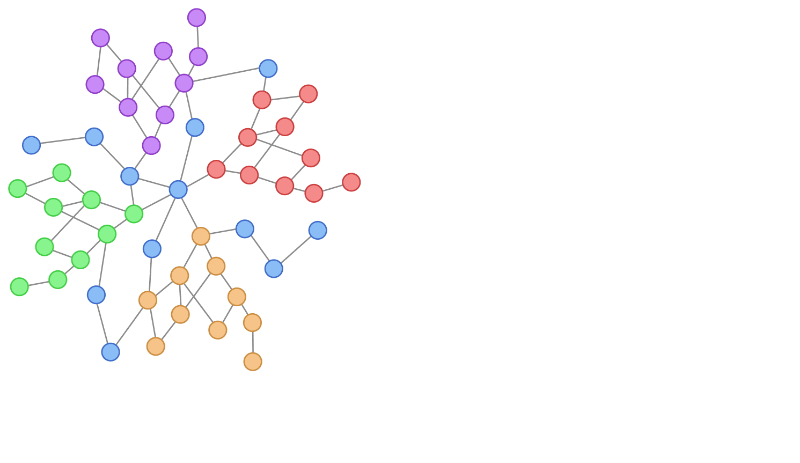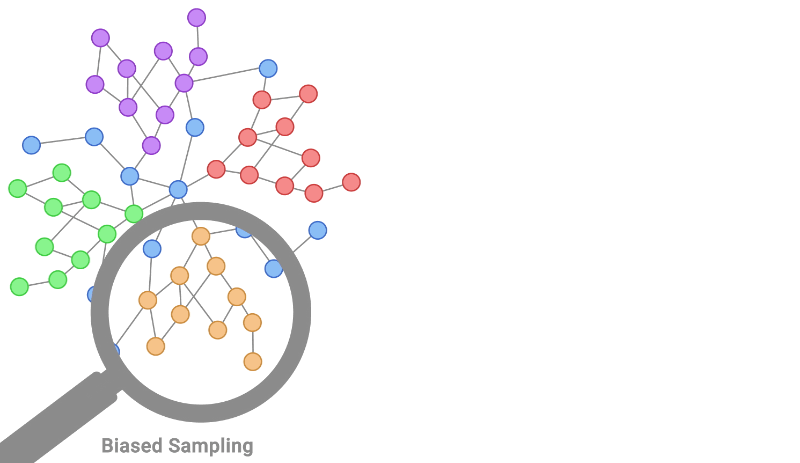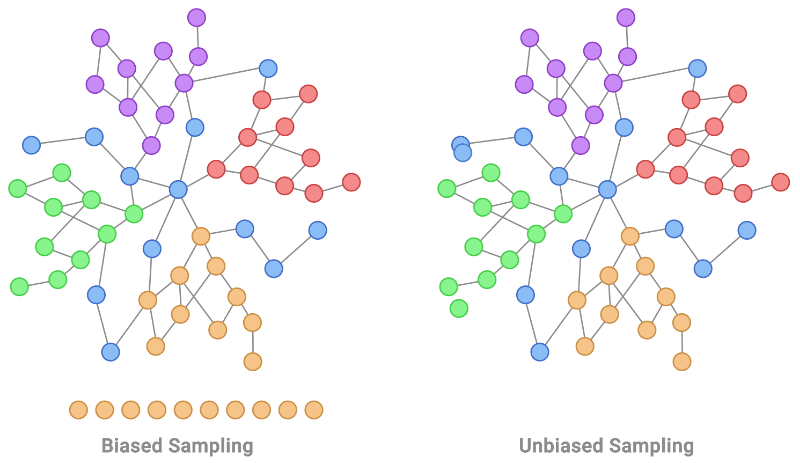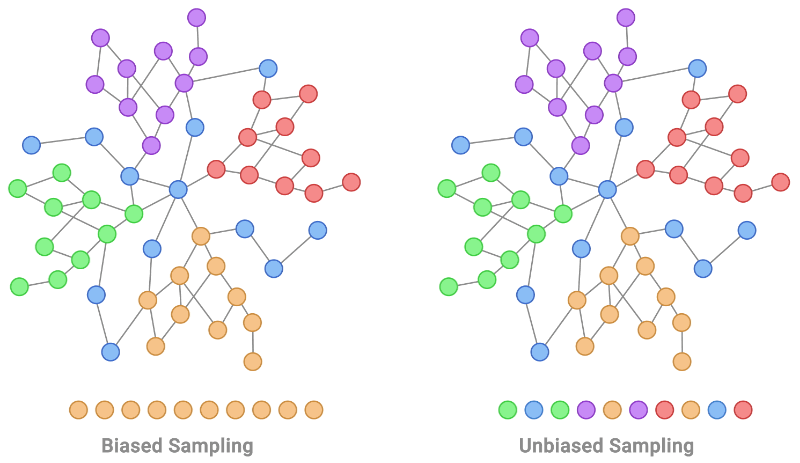 |
| Localized coaching information is a typical non-IID bias exhibited in graph-structured information. That is proven on the left determine by taking an orange node and increasing to these round it. As a substitute, an IID coaching pattern of nodes for labeling could be uniformly distributed, as illustrated by the sampling course of on the proper. |
To quantify the quantity of bias current in a coaching set, one can use strategies that measure how massive the shift is between two completely different likelihood distributions, the place the scale of the shift may be regarded as the quantity of bias. Because the shift grows in measurement, machine studying fashions have extra problem generalizing from the biased coaching set. This case can meaningfully damage generalizability — on educational datasets, we’ve noticed area shifts inflicting a efficiency drop of 15-20% (as measured by the F1 rating).
In “Shift-Strong GNNs: Overcoming the Limitations of Localized Graph Coaching Information”, offered at NeurIPS 2021, we introduce an answer for utilizing GNNs on biased information. Known as Shift-Strong GNN (SR-GNN), this method is designed to account for distributional variations between biased coaching information and a graph’s true inference distribution. SR-GNN adapts GNN fashions to the presence of distributional shift between the nodes labeled for coaching and the remainder of the dataset. We illustrate the effectiveness of SR-GNN in a wide range of experiments with biased coaching datasets on frequent GNN benchmark datasets for semi-supervised studying and present that SR-GNN outperforms different GNN baselines in accuracy, lowering the detrimental results of biased coaching information by 30–40%.
The Impression of Distribution Shifts on Efficiency
To display how distribution shift impacts GNN efficiency, we first generate a lot of biased coaching units for identified educational datasets. Then with a view to perceive the impact, we plot the generalization (take a look at accuracy) versus a measure of distribution shift (the Central Second Discrepancy1, CMD). For instance, take into account the well-known PubMed quotation dataset, which may be regarded as a graph the place the nodes are medical analysis papers and the sides characterize citations between them. Once we generate biased coaching information for PubMed, the plot seems like this:
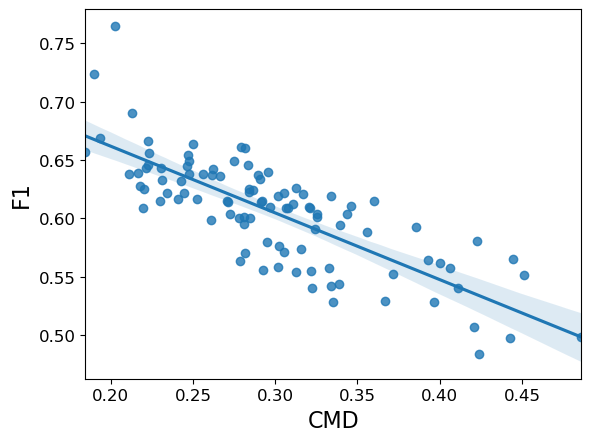 |
| The impact of distribution shift on the PubMed dataset. Efficiency (F1) is proven on the y-axis vs. the distribution shift, Central Second Discrepancy (CMD), on the x-axis, for 100 biased coaching set samples. Because the distribution shift will increase, the mannequin’s accuracy falls. |
Right here one can observe a robust detrimental correlation between the distribution shift within the dataset and the classification accuracy: as CMD will increase, the efficiency (F1) decreases. That’s, GNNs can have problem generalizing as their coaching information seems much less just like the take a look at dataset.
To handle this, we suggest a shift-robust regularizer (comparable in concept to domain-invariant studying) to attenuate the distribution shift between coaching information and an IID pattern from unlabeled information. To do that, we measure the area shift (e.g., by way of CMD) in actual time because the mannequin is coaching and apply a direct penalty based mostly on this that forces the mannequin to disregard as a lot of the coaching bias as doable. This forces the function encoders that the mannequin learns for the coaching information to additionally work successfully for any unlabeled information, which could come from a distinct distribution.
The determine under exhibits what this seems like when in comparison with a conventional GNN mannequin. We nonetheless have the identical inputs (the node options X, and the Adjacency Matrix A), and the identical variety of layers. Nevertheless on the last embedding Zok from layer (ok) of the GNN is in contrast towards embeddings from unlabeled information factors to confirm that the mannequin is appropriately encoding them.
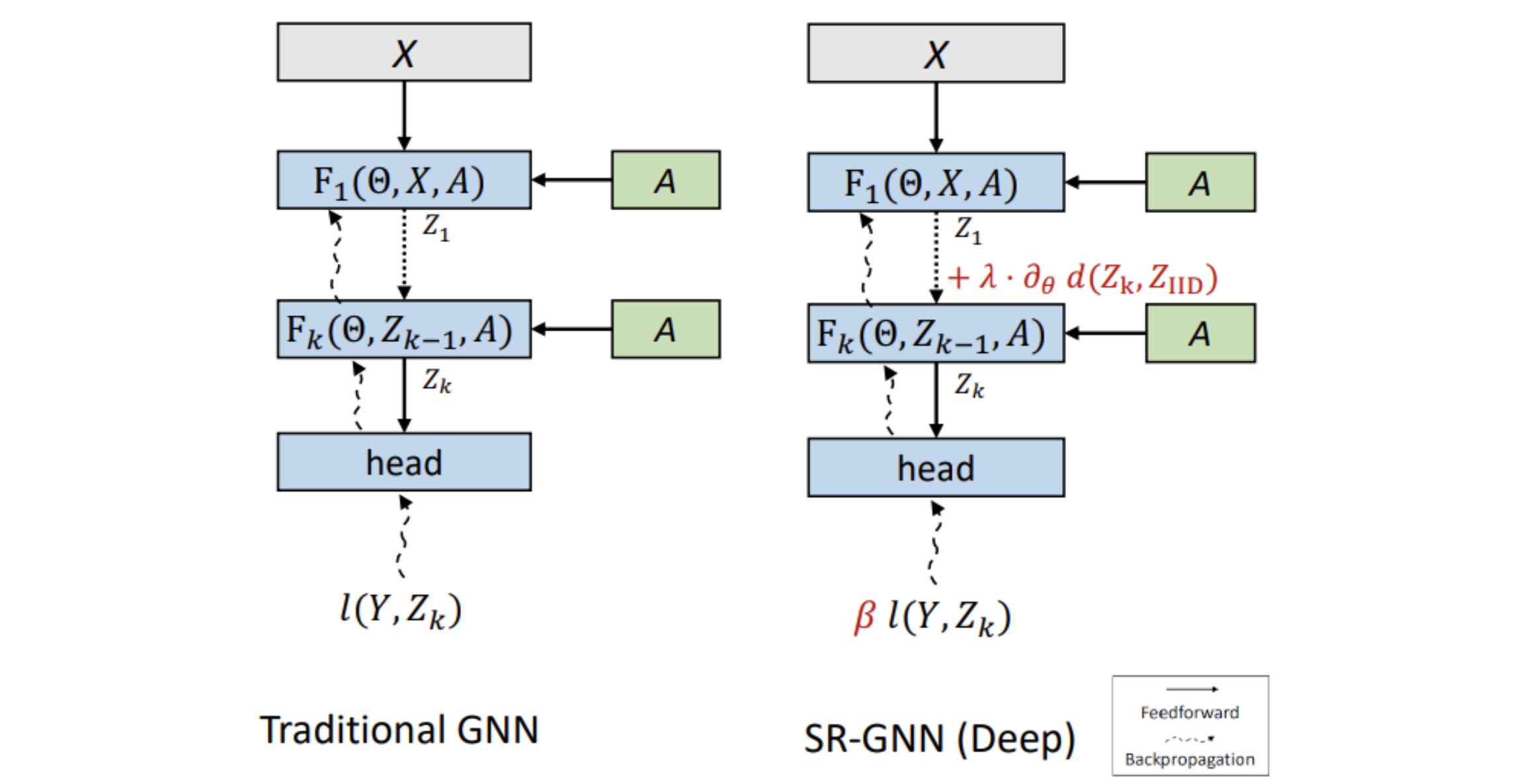 |
| SR-GNN provides two sorts of regularizations to deep GNN fashions. First, a site shift regularization (λ time period) minimizes the space between hidden representations of the labeled (Zok) and unlabeled (ZIID) information. Second, the occasion weight (β) of the examples may be modified to additional approximate the true distribution. |
We write this regularization as an extra time period within the system for the mannequin’s loss based mostly on the space between the coaching information’s representations and the true information’s distribution (full formulation accessible within the paper).
In our experiments, we examine our technique and a lot of normal graph neural community fashions, to measure their efficiency on node classification duties. We display that including the SR-GNN regularization provides a 30–40% p.c enchancment on classification duties with biased coaching information labels.
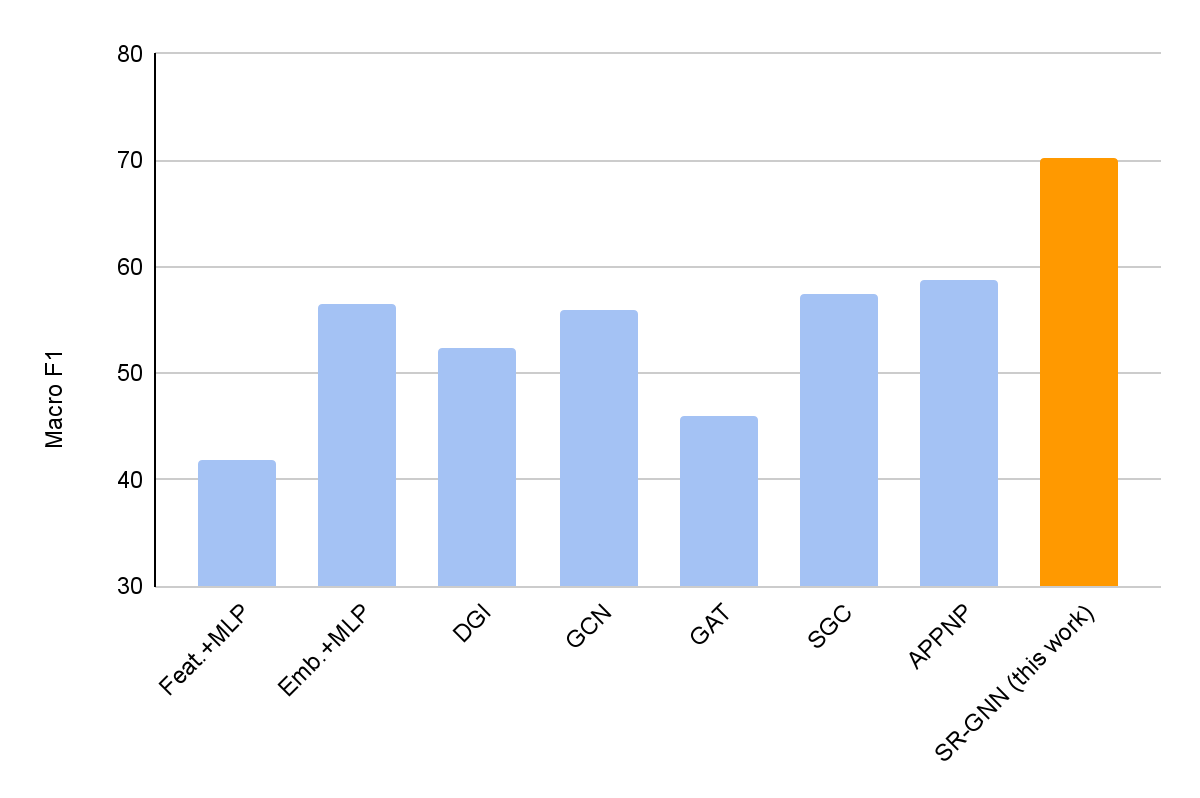 |
| A comparability of SR-GNN utilizing node classification with biased coaching information on the PubMed dataset. SR-GNN outperforms seven baselines, together with DGI, GCN, GAT, SGC and APPNP. |
Shift-Strong Regularization for Linear GNNs by way of Occasion Re-weighting
Furthermore, it’s value noting that there’s one other class of GNN fashions (e.g., APPNP, SimpleGCN, and so on) which can be based mostly on linear operations to hurry up their graph convolutions. We additionally examined how you can make these fashions extra dependable within the presence of biased coaching information. Whereas the identical regularization mechanism can’t be straight utilized because of their completely different structure, we are able to “right” the coaching bias by re-weighting the coaching situations based on their distance from an approximated true distribution. This permits correcting the distribution of the biased coaching information with out passing gradients via the mannequin.
Lastly, the 2 regularizations — for each deep and linear GNNs — may be mixed right into a generalized regularization for the loss, which mixes each area regularization and occasion reweighting (particulars, together with the loss formulation, accessible within the paper).
Conclusion
Biased coaching information is frequent in actual world situations and may come up because of a wide range of causes, together with difficulties of labeling a considerable amount of information, the varied heuristics or inconsistent strategies which can be used to decide on nodes for labeling, delayed label task, and others. We offered a common framework (SR-GNN) that may scale back the affect of biased coaching information and may be utilized to varied sorts of GNNs, together with each deeper GNNs and newer linearized (shallow) variations of those fashions.
Acknowledgements
Qi Zhu is a PhD Scholar at UIUC. Because of our collaborators Natalia Ponomareva (Google Analysis) and Jiawei Han (UIUC). Because of Tom Small and Anton Tsitsulin for visualizations.
1We observe that many measures of distribution shift have been proposed within the literature. Right here we use CMD (as it’s fast to calculate and customarily exhibits good efficiency within the area adaptation literature), however the idea generalizes to any measure of distribution distances/area shift. ↩
[ad_2]