Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

[ad_1]
Social community evaluation is shortly turning into an essential device to serve a wide range of skilled wants. It could inform company objectives resembling focused advertising and marketing and establish safety or reputational dangers. Social community evaluation can even assist companies meet inside objectives: It supplies perception into worker behaviors and the relationships amongst completely different components of an organization.
Organizations can make use of a variety of software program options for social community evaluation; every has its execs and cons, and is suited to completely different functions. This text focuses on Microsoft’s Energy BI, some of the generally used knowledge visualization instruments at this time. Whereas Energy BI affords many social community add-ons, we’ll discover customized visuals in R to create extra compelling and versatile outcomes.
This tutorial assumes an understanding of primary graph idea, significantly directed graphs. Additionally, later steps are finest suited to Energy BI Desktop, which is just accessible on Home windows. Readers might use the Energy BI browser on Mac OS or Linux, however the Energy BI browser doesn’t help sure options, resembling importing an Excel workbook.
Creating social networks begins with the gathering of connections (edge) knowledge. Connections knowledge comprises two main fields: the supply node and the goal node—the nodes at both finish of the sting. Past these nodes, we will gather knowledge to supply extra complete visible insights, usually represented as node or edge properties:
1) Node properties
2) Edge properties
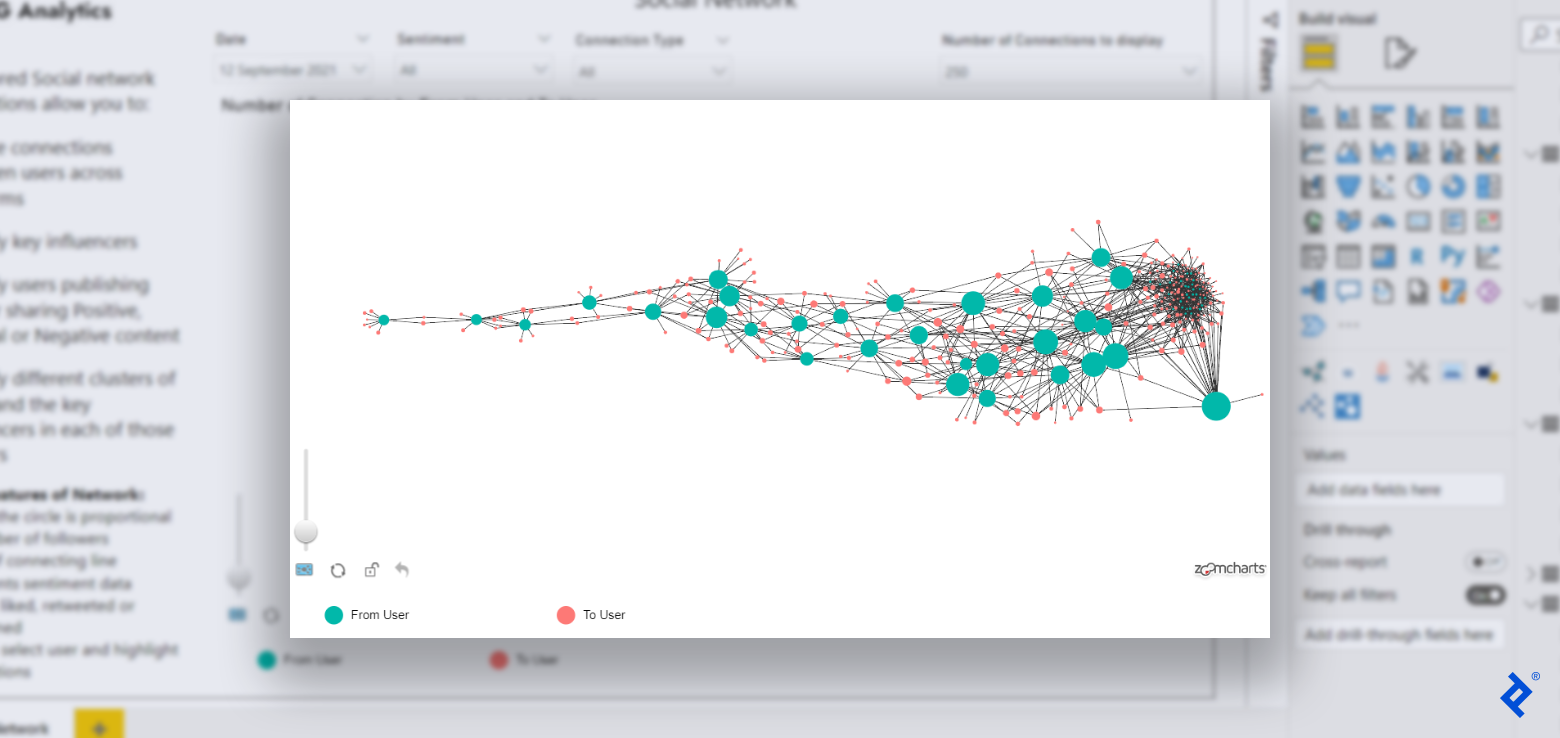
Let’s examine an instance social community visible to see how these properties perform:
We will additionally use hover textual content to complement or change the above parameters, as it could actually help different data that can’t be simply expressed by way of node or edge properties.
Having outlined the completely different knowledge options of a social community, let’s look at the professionals and cons of 4 standard instruments used to visualise networks in Energy BI.
| Extension | Social Community Graph by Arthur Graus | Community Navigator | Superior Networks by ZoomCharts (Gentle Version) | Customized Visualizations Utilizing R |
|---|---|---|---|---|
| Dynamic node measurement | Sure | Sure | Sure | Sure |
| Dynamic edge measurement | No | Sure | No | Sure |
| Node coloration customization | Sure | Sure | No | Sure |
| Complicated social community processing | No | Sure | Sure | Sure |
| Profile photos for nodes | Sure | No | No | Sure |
| Adjustable zoom | No | Sure | Sure | Sure |
| Prime N connections filtering | No | No | No | Sure |
| Customized data on hover | No | No | No | Sure |
| Edge coloration customization | No | No | No | Sure |
| Different superior options | No | No | No | Sure |
Social Community Graph by Arthur Graus, Community Navigator, and Superior Networks by ZoomCharts (Gentle Version) are all appropriate extensions to develop easy social networks and get began along with your first social community evaluation.
Nonetheless, if you wish to make your knowledge come alive and uncover groundbreaking insights with attention-grabbing visuals, or in case your social community is especially complicated, I like to recommend growing your customized visuals in R.
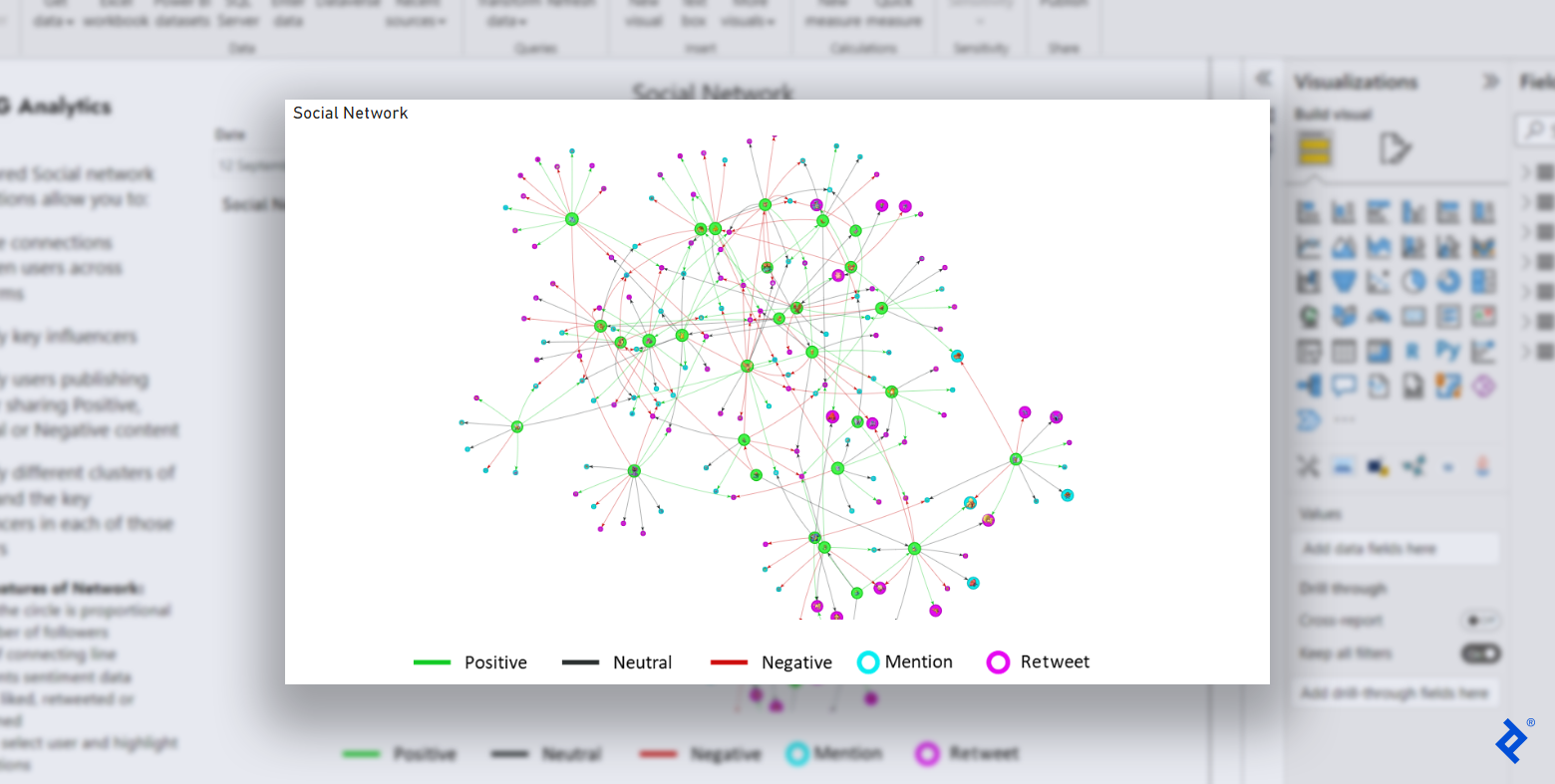
This tradition visualization is the ultimate results of our tutorial’s social community extension in R and demonstrates the big number of options and node/edge properties provided by R.
Creating an extension to visualise social networks in Energy BI utilizing R includes 5 distinct steps. However earlier than we will construct our social community extension, we should load our knowledge into Energy BI.
You’ll be able to comply with this tutorial with a check dataset based mostly on Twitter and Fb knowledge or proceed with your individual social community. Our knowledge has been randomized; you could obtain actual Twitter knowledge if desired. After you gather the required knowledge, add it into Energy BI (for instance, by importing an Excel workbook or including knowledge manually). Your outcome ought to look much like the next desk:
Upon getting your knowledge arrange, you might be able to create a customized visualization.
Creating a Energy BI visualization will not be easy—even primary visuals require hundreds of information. Luckily, Microsoft affords a library referred to as pbiviz, which supplies the required infrastructure-supporting information with only some traces of code. The pbiviz library may even repackage all of our last information right into a .pbiviz file that we will load straight into Energy BI as a visualization.
The only option to set up pbiviz is with Node.js. As soon as pbiviz is put in, we have to initialize our customized R visible by way of our machine’s command-line interface:
pbiviz new toptalSocialNetworkByBharatGarg -t rhtml
cd toptalSocialNetworkByBharatGarg
npm set up
pbiviz package deal
Don’t neglect to switch toptalSocialNetworkByBharatGarg with the specified identify to your visualization. -t rhtml informs the pbiviz package deal that it ought to create a template to develop R-based HTML visualizations. You will notice errors as a result of we have now not but specified fields such because the writer’s identify and electronic mail in our package deal, however we are going to resolve these later within the tutorial. If the pbiviz script gained’t run in any respect in PowerShell, you first might have to permit scripts with Set-ExecutionPolicy RemoteSigned.
On profitable execution of the code, you will notice a folder with the next construction:
As soon as we have now the folder construction prepared, we will write the R code for our customized visualization.
The listing created in step one comprises a file named script.r, which consists of default code. (The default code creates a easy Energy BI extension, which makes use of the iris pattern database accessible in R to plot a histogram of Petal.Size by Petal.Species.) We are going to replace the code however retain its default construction, together with its commented sections.
Our challenge makes use of three R libraries:
Let’s change the code within the Library Declarations part of script.r to mirror our library utilization:
libraryRequireInstall("DiagrammeR")
libraryRequireInstall("visNetwork")
libraryRequireInstall("knowledge.desk")
Subsequent, we are going to change the code within the Precise code part with our R code. Earlier than creating our visualization, we should first learn and course of our knowledge. We are going to take two inputs from Energy BI:
num_records: The numeric enter N, such that we are going to choose solely the highest N connections from our community (to restrict the variety of connections displayed)dataset: Our social community nodes and edgesTo calculate the N connections that we are going to plot, we have to mixture the num_records worth as a result of Energy BI will present a vector by default as an alternative of a single numeric worth. An aggregation perform like max achieves this purpose:
limit_connection <- max(num_records)
We are going to now learn dataset as a knowledge.desk object with customized columns. We type the dataset by worth in reducing order to put essentially the most frequent connections on the prime of the desk. This ensures that we select a very powerful data to plot once we restrict our connections with num_records:
dataset <- knowledge.desk(from = dataset[[1]]
,to = dataset[[2]]
,worth = dataset[[3]]
,col_sentiment = dataset[[4]]
,col_type = dataset[[5]]
,from_name = dataset[[6]]
,to_name = dataset[[7]]
,from_avatar = dataset[[8]]
,to_avatar = dataset[[9]])[
order(-value)][
seq(1, min(nrow(dataset), limit_connection))]
Subsequent, we should put together our person data by creating and allocating distinctive person IDs (uid) to every person, storing these in a brand new desk. We additionally calculate the whole variety of customers and retailer that data in a separate variable referred to as num_nodes:
user_ids <- knowledge.desk(id = distinctive(c(dataset$from,
dataset$to)))[, uid := 1:.N]
num_nodes <- nrow(user_ids)
Let’s replace our person data with extra properties, together with:
We are going to use R’s merge perform to replace the desk:
user_ids <- merge(user_ids, dataset[, .(num_follower = uniqueN(to)), from], by.x = 'id', by.y = 'from', all.x = T)[is.na(num_follower), num_follower := 0][, size := num_follower][num_follower > 0, size := size + 50][, size := size + 10]
user_ids <- merge(user_ids, dataset[, .(sum_val = sum(value)), .(to, col_type)][order(-sum_val)][, id := 1:.N, to][id == 1, .(to, col_type)], by.x = 'id', by.y = 'to', all.x = T)
user_ids[id %in% dataset$from, col_type := '#42f548']
user_ids <- merge(user_ids, distinctive(rbind(dataset[, .('id' = from, 'Name' = from_name, 'avatar' = from_avatar)],
dataset[, .('id' = to, 'Name' = to_name, 'avatar' = to_avatar)])),
by = 'id')
We additionally add our created uid to the unique dataset in order that we will retrieve the from and to person IDs later within the code:
dataset <- merge(dataset, user_ids[, .(id, uid)],
by.x = "from", by.y = "id")
dataset <- merge(dataset, user_ids[, .(id, uid_retweet = uid)],
by.x = "to", by.y = "id")
user_ids <- user_ids[order(uid)]
Subsequent, we create node and edge knowledge frames for the visualization. We select the model and form of our nodes (stuffed circles), and choose the right columns of our user_ids desk to populate our nodes’ coloration, knowledge, worth, and picture attributes:
nodes <- create_node_df(n = num_nodes,
sort = "decrease",
model = "stuffed",
coloration = user_ids$col_type,
form="circularImage",
knowledge = user_ids$uid,
worth = user_ids$measurement,
picture = user_ids$avatar,
title = paste0("<p>Identify: <b>", user_ids$Identify,"</b><br>",
"Tremendous UID <b>", user_ids$id, "</b><br>",
"# followers <b>", user_ids$num_follower, "</b><br>",
"</p>")
)
Equally, we choose the dataset desk columns that correspond to our edges’ from, to, and coloration attributes:
edges <- create_edge_df(from = dataset$uid,
to = dataset$uid_retweet,
arrows = "to",
coloration = dataset$col_sentiment)
Lastly, with the node and edge knowledge frames prepared, let’s create our visualization utilizing the visNetwork library and retailer it in a variable the default code will use later, referred to as p:
p <- visNetwork(nodes, edges) %>%
visOptions(highlightNearest = record(enabled = TRUE, diploma = 1, hover = T)) %>%
visPhysics(stabilization = record(enabled = FALSE, iterations = 10), adaptiveTimestep = TRUE, barnesHut = record(avoidOverlap = 0.2, damping = 0.15, gravitationalConstant = -5000))
Right here, we customise a couple of community visualization configurations in visOptions and visPhysics. Be at liberty to look by way of the documentation pages and replace these choices as desired. Our Precise code part is now full, and we must always replace the Create and save widget part by eradicating the road p = ggplotly(g); since we coded our personal visualization variable, p.
Now that we have now completed coding in R, we should make sure modifications in our supporting JSON information to arrange the visualization to be used in Energy BI.
Let’s begin with the capabilities.json file. It consists of many of the data you see within the Visualizations tab for a visible, resembling our extension’s knowledge sources and different settings. First, we have to replace dataRoles and change the prevailing worth with new knowledge roles for our dataset and num_records inputs:
# ...
"dataRoles": [
{
"displayName": "dataset",
"description": "Connection Details - From, To, # of Connections, Sentiment Color, To Node Type Color",
"kind": "GroupingOrMeasure",
"name": "dataset"
},
{
"displayName": "num_records",
"description": "number of records to keep",
"kind": "Measure",
"name": "num_records"
}
],
# ...
In our capabilities.json file, let’s additionally replace the dataViewMappings part. We’ll add circumstances that our inputs should adhere to, in addition to replace the scriptResult to match our new knowledge roles and their circumstances. See the circumstances part, together with the choose part below scriptResult, for modifications:
# ...
"dataViewMappings": [
{
"conditions": [
{
"dataset": {
"max": 20
},
"num_records": {
"max": 1
}
}
],
"scriptResult": {
"dataInput": {
"desk": {
"rows": {
"choose": [
{
"for": {
"in": "dataset"
}
},
{
"for": {
"in": "num_records"
}
}
],
"dataReductionAlgorithm": {
"prime": {}
}
}
}
},
# ...
Let’s transfer on to our dependencies.json file. Right here, we are going to add three extra packages below cranPackages in order that Energy BI can establish and set up the required libraries:
{
"identify": "knowledge.desk",
"displayName": "knowledge.desk",
"url": "https://cran.r-project.org/net/packages/knowledge.desk/index.html"
},
{
"identify": "DiagrammeR",
"displayName": "DiagrammeR",
"url": "https://cran.r-project.org/net/packages/DiagrammeR/index.html"
},
{
"identify": "visNetwork",
"displayName": "visNetwork",
"url": "https://cran.r-project.org/net/packages/visNetwork/index.html"
},
Be aware: Energy BI ought to mechanically set up these libraries, however if you happen to encounter library errors, strive operating the next command:
set up.packages(c("DiagrammeR", "htmlwidgets", "visNetwork", "knowledge.desk", "xml2"))
Lastly, let’s add related data for our visible to the pbiviz.json file. I’d suggest updating the next fields:
Now, our information have been up to date, and we should repackage the visualization from the command line:
pbiviz package deal
On profitable execution of the code, a .pbiviz file needs to be created within the dist listing. Your complete code coated on this tutorial may be considered on GitHub.
To import your new visualization in Energy BI, open your Energy BI report (both one for current knowledge or one created throughout our Prerequisite step with check knowledge) and navigate to the Visualizations tab. Click on the … [more options] button and choose Import a visible from a file. Be aware: Chances are you’ll must first choose Edit in a browser to ensure that the Visualizations tab to be seen.
Navigate to the dist listing of your visualization folder and choose the .pbiviz file to seamlessly load your visible into Energy BI.
The visualization that you just imported is now accessible within the visualizations pane. Click on on the visualization icon so as to add it to your report, after which add related columns to the dataset and num_records inputs:
You’ll be able to add extra textual content, filters, and options to your visualization relying in your challenge necessities. I additionally suggest that you just undergo the detailed documentation for the three R libraries we used to additional improve your visualizations, since our instance challenge can’t cowl all use circumstances of the accessible features.
Our last result’s a testomony to the facility and effectivity of R with regards to creating customized Energy BI visualizations. Check out social community evaluation utilizing customized visuals in R in your subsequent dataset, and make smarter choices with complete knowledge insights.
The Toptal Engineering Weblog extends its gratitude to Leandro Roser for reviewing the code samples introduced on this article.
[ad_2]