Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

[ad_1]
In legacy relational database administration programs, knowledge is saved in a number of advanced knowledge varieties, such XML, JSON, BLOB, or CLOB. This knowledge may comprise helpful info that’s usually troublesome to remodel into insights, so that you is perhaps in search of methods to load and use this knowledge in a contemporary cloud knowledge warehouse similar to Amazon Redshift. One such instance is migrating knowledge from a legacy Oracle database with XML BLOB fields to Amazon Redshift, by performing preprocessing and conversion of XML to JSON utilizing Amazon EMR. On this submit, we describe an answer structure for this use case, and present you tips on how to implement the code to deal with the XML conversion.
Step one in any knowledge migration challenge is to seize and ingest the info from the supply database. For this process, we use AWS Database Migration Service (AWS DMS), a service that helps you migrate databases to AWS shortly and securely. On this instance, we use AWS DMS to extract knowledge from an Oracle database with XML BLOB fields and stage the identical knowledge in Amazon Easy Storage Service (Amazon S3) in Apache Parquet format. Amazon S3 is an object storage service providing industry-leading scalability, knowledge availability, safety, and efficiency, and is the storage of selection for establishing knowledge lakes on AWS.
After the info is ingested into an S3 staging bucket, we used Amazon EMR to run a Spark job to carry out the conversion of XML fields to JSON fields, and the outcomes are loaded in a curated S3 bucket. Amazon EMR runtime for Apache Spark might be over 3 times sooner than clusters with out EMR runtime, and has 100% API compatibility with normal Apache Spark. This improved efficiency means your workloads run sooner and it saves you compute prices, with out making any adjustments to your software.
Lastly, reworked and curated knowledge is loaded into Amazon Redshift tables utilizing the COPY command. The Amazon Redshift desk construction ought to match the variety of columns and the column knowledge varieties within the supply file. As a result of we saved the info as a Parquet file, we specify the SERIALIZETOJSON choice within the COPY command. This enables us to load advanced varieties, similar to construction and array, in a column outlined as SUPER knowledge kind within the desk.
The next structure diagram exhibits the end-to-end workflow.

Intimately, AWS DMS migrates knowledge from the supply database tables into Amazon S3, in Parquet format. Apache Spark on Amazon EMR reads the uncooked knowledge, transforms the XML knowledge kind into JSON, and saves the info to the curated S3 bucket. In our code, we used an open-source library, referred to as spark-xml, to parse and question the XML knowledge.
In the remainder of this submit, we assume that the AWS DMS duties have already run and created the supply Parquet recordsdata within the S3 staging bucket. If you wish to arrange AWS DMS to learn from an Oracle database with LOB fields, discuss with Successfully migrating LOB knowledge to Amazon S3 from Amazon RDS for Oracle with AWS DMS or watch the video Migrate Oracle to S3 Information lake through AWS DMS.
If you wish to comply with together with the examples on this submit utilizing your AWS account, we offer an AWS CloudFormation template you may launch by selecting Launch Stack:
![]()
Present a stack identify and depart the default settings for every part else. Await the stack to show Create Full (this could solely take a couple of minutes) earlier than transferring on to the opposite sections.
The template creates the next sources:
{stackname}-s3bucket-{xxx}, which incorporates the next folders:
libs – Comprises the JAR file so as to add to the pocket booknotebooks – Comprises the pocket book to interactively check the codeknowledge – Comprises the pattern knowledgers_xml_db and a schema named rs_xmlrs_xml_db) in AWS Secrets and techniques SupervisorThe CloudFormation template shared on this submit is only for demonstration functions solely. Please conduct your personal safety assessment and incorporate greatest practices previous to any manufacturing deployment utilizing artifacts from the submit.
Lastly, some primary data of Python and Spark DataFrames may also help you assessment the transformation code, however isn’t obligatory to finish the instance.
On this submit, we use school college students’ course and topics pattern knowledge that we created. Within the supply system, knowledge consists of flat construction fields, like course_id and course_name, and an XML area that features all of the course materials and topics concerned within the respective course. The next screenshot is an instance of the supply knowledge, which is staged in an S3 bucket as a prerequisite step.

We are able to observe that the column study_material_info is an XML kind area and incorporates nested XML tags in it. Let’s see tips on how to convert this nested XML area to JSON within the subsequent steps.
On this step, we use an Amazon EMR pocket book, which is a managed setting to create and open Jupyter Pocket book and JupyterLab interfaces. It allows you to interactively analyze and visualize knowledge, collaborate with friends, and construct purposes utilizing Apache Spark on EMR clusters. To open the pocket book, comply with these steps:


BDB1909-EMR-LIVY-SG and BDB1909-EMR-Pocket book-SGbdb1909-emrNotebookRole-{xxx}.s3://{stackname}-s3bucket-xxx}/notebooks/).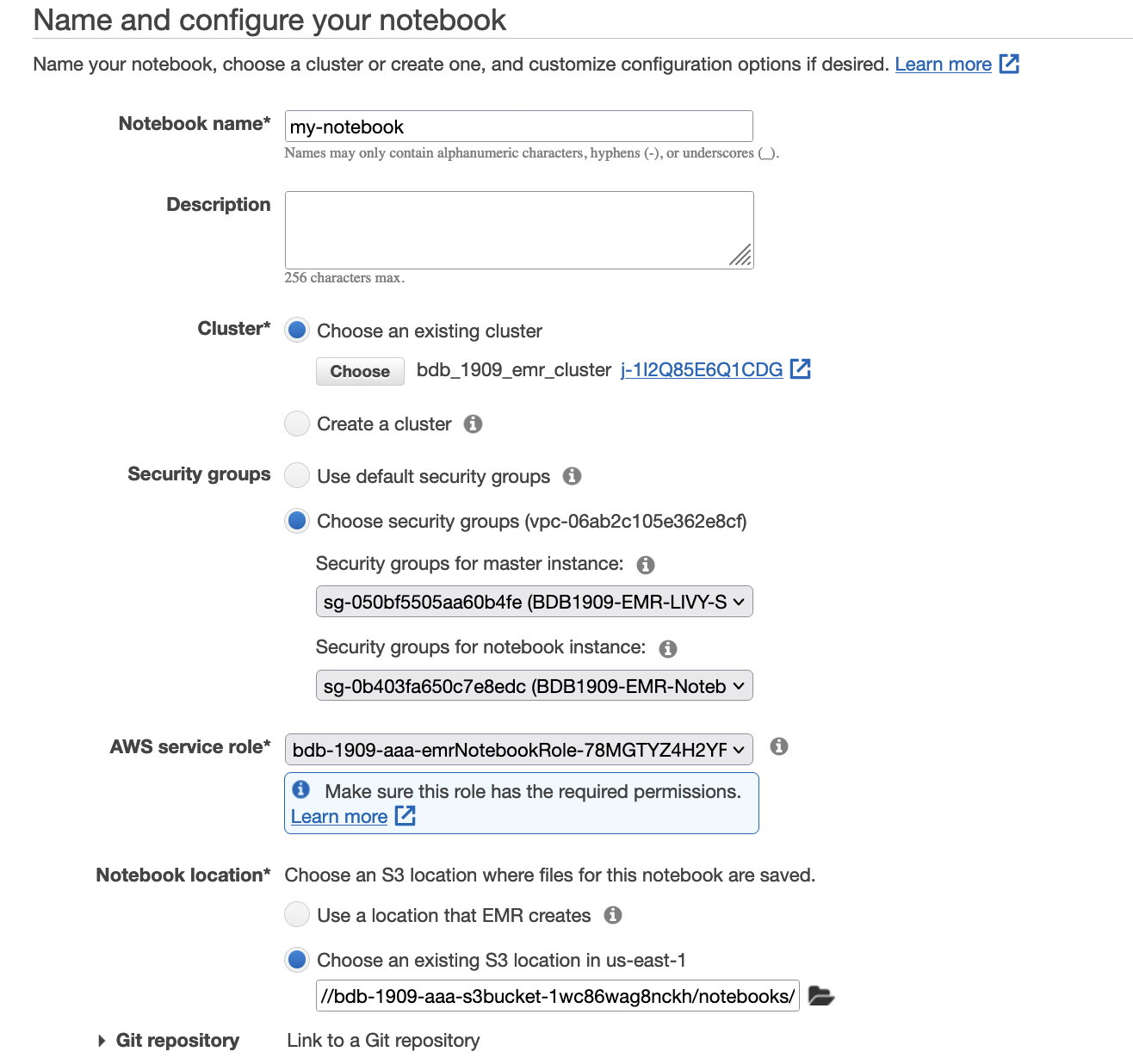




spark-xml bundle permits studying XML recordsdata in native or distributed file programs as Spark DataFrames. Though primarily used to transform (parts of) giant XML paperwork right into a DataFrame, spark-xml also can parse XML in a string-valued column in an current DataFrame with the from_xml perform, so as to add it as a brand new column with parsed outcomes as a struct.STUDY_MATERIAL_INFO) and map it to a string variable identify payloadSchema.payloadSchema within the from_xml perform to transform the sphere STUDY_MATERIAL_INFO right into a struct knowledge kind and added it as a column named course_material in a brand new DataFrame parsed.curated zone in Amazon S3.As a result of construction variations between DataFrame and XML, there are some conversion guidelines from XML knowledge to DataFrame and from DataFrame to XML knowledge. Extra particulars and documentation can be found XML Information Supply for Apache Spark.
After we convert from XML to DataFrame, attributes are transformed as fields with the heading prefix attributePrefix (underscore (_) is the default). For instance, see the next code:
It produces the next schema:
Subsequent, we’ve got a price in a component that has no youngster components however attributes. The worth is put in a separate area, valueTag. See the next code:
It produces the next schema, and the tag lang is transformed into the _lang area contained in the DataFrame:
As a result of our semi-structured nested dataset is already written within the S3 bucket as Apache Parquet formatted recordsdata, we will use the COPY command with the SERIALIZETOJSON choice to ingest knowledge into Amazon Redshift. The Amazon Redshift desk construction ought to match the metadata of the Parquet recordsdata. Amazon Redshift can exchange any Parquet columns, together with construction and array varieties, with SUPER knowledge columns.
The next code demonstrates CREATE TABLE instance to create a staging desk.
The next code makes use of the COPY instance to load from Parquet format:
By utilizing semistructured knowledge assist in Amazon Redshift, you may ingest and retailer semistructured knowledge in your Amazon Redshift knowledge warehouses. With the SUPER knowledge kind and PartiQL language, Amazon Redshift expands the info warehouse functionality to combine with each SQL and NoSQL knowledge sources. The SUPER knowledge kind solely helps as much as 1 MB of knowledge for a person SUPER area or object. Word, the JSON object could also be saved in a SUPER knowledge kind, however studying this knowledge utilizing JSON features at present has a VARCHAR (65535 byte) restrict. See Limitations for extra particulars.
The next instance exhibits how nested JSON might be simply accessed utilizing SELECT statements:
The next screenshot exhibits our outcomes.

To keep away from incurring future fees, first delete the pocket book and the associated recordsdata on Amazon S3 bucket as defined in this EMR documentation web page then the CloudFormation stack.
This submit demonstrated tips on how to use AWS companies like AWS DMS, Amazon S3, Amazon EMR, and Amazon Redshift to seamlessly work with advanced knowledge varieties like XML and carry out historic migrations when constructing a cloud knowledge lake home on AWS. We encourage you to do this resolution and benefit from all the advantages of those purpose-built companies.
When you have questions or strategies, please depart a remark.
 Abhilash Nagilla is a Sr. Specialist Options Architect at AWS, serving to public sector clients on their cloud journey with a give attention to AWS analytics companies. Exterior of labor, Abhilash enjoys studying new applied sciences, watching films, and visiting new locations.
Abhilash Nagilla is a Sr. Specialist Options Architect at AWS, serving to public sector clients on their cloud journey with a give attention to AWS analytics companies. Exterior of labor, Abhilash enjoys studying new applied sciences, watching films, and visiting new locations.
 Avinash Makey is a Specialist Options Architect at AWS. He helps clients with knowledge and analytics options in AWS. Exterior of labor he performs cricket, tennis and volleyball in free time.
Avinash Makey is a Specialist Options Architect at AWS. He helps clients with knowledge and analytics options in AWS. Exterior of labor he performs cricket, tennis and volleyball in free time.
 Fabrizio Napolitano is a Senior Specialist SA for DB and Analytics. He has labored within the analytics house for the final 20 years, and has not too long ago and fairly abruptly change into a Hockey Dad after transferring to Canada.
Fabrizio Napolitano is a Senior Specialist SA for DB and Analytics. He has labored within the analytics house for the final 20 years, and has not too long ago and fairly abruptly change into a Hockey Dad after transferring to Canada.
[ad_2]