Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

[ad_1]
Over the previous a number of years, deep neural networks (DNNs) have been fairly profitable in driving spectacular efficiency features in a number of real-world purposes, from picture recognition to genomics. Nonetheless, trendy DNNs usually have much more trainable mannequin parameters than the variety of coaching examples and the ensuing overparameterized networks can simply overfit to noisy or corrupted labels (i.e., examples which might be assigned a fallacious class label). As a consequence, coaching with noisy labels usually results in degradation in accuracy of the educated mannequin on clear check information. Sadly, noisy labels can seem in a number of real-world situations as a result of a number of elements, corresponding to errors and inconsistencies in guide annotation and the usage of inherently noisy label sources (e.g., the web or automated labels from an current system).
Earlier work has proven that representations realized by pre-training massive fashions with noisy information could be helpful for prediction when utilized in a linear classifier educated with clear information. In precept, it’s potential to instantly prepare machine studying (ML) fashions on noisy information with out resorting to this two-stage method. To achieve success, such various strategies ought to have the next properties: (i) they need to match simply into customary coaching pipelines with little computational or reminiscence overhead; (ii) they need to be relevant in “streaming” settings the place new information is repeatedly added throughout coaching; and (iii) they need to not require information with clear labels.
In “Constrained Occasion and Class Reweighting for Strong Studying below Label Noise”, we suggest a novel and principled technique, named Constrained Occasion reWeighting (CIW), with these properties that works by dynamically assigning significance weights each to particular person cases and to class labels in a mini-batch, with the purpose of lowering the impact of probably noisy examples. We formulate a household of constrained optimization issues that yield easy options for these significance weights. These optimization issues are solved per mini-batch, which avoids the necessity to retailer and replace the significance weights over the complete dataset. This optimization framework additionally gives a theoretical perspective for current label smoothing heuristics that tackle label noise, corresponding to label bootstrapping. We consider the strategy with various quantities of artificial noise on the usual CIFAR-10 and CIFAR-100 benchmarks and observe appreciable efficiency features over a number of current strategies.
Technique
Coaching ML fashions includes minimizing a loss perform that signifies how effectively the present parameters match to the given coaching information. In every coaching step, this loss is roughly calculated as a (weighted) sum of the losses of particular person cases within the mini-batch of information on which it’s working. In customary coaching, every occasion is handled equally for the aim of updating the mannequin parameters, which corresponds to assigning uniform (i.e., equal) weights throughout the mini-batch.
Nonetheless, empirical observations made in earlier works reveal that noisy or mislabeled cases are inclined to have greater loss values than these which might be clear, significantly throughout early to mid-stages of coaching. Thus, assigning uniform significance weights to all cases implies that as a result of their greater loss values, the noisy cases can doubtlessly dominate the clear cases and degrade the accuracy on clear check information.
Motivated by these observations, we suggest a household of constrained optimization issues that remedy this downside by assigning significance weights to particular person cases within the dataset to cut back the impact of these which might be prone to be noisy. This method gives management over how a lot the weights deviate from uniform, as quantified by a divergence measure. It seems that for a number of kinds of divergence measures, one can get hold of easy formulae for the occasion weights. The ultimate loss is computed because the weighted sum of particular person occasion losses, which is used for updating the mannequin parameters. We name this the Constrained Occasion reWeighting (CIW) technique. This technique permits for controlling the smoothness or peakiness of the weights by the selection of divergence and a corresponding hyperparameter.
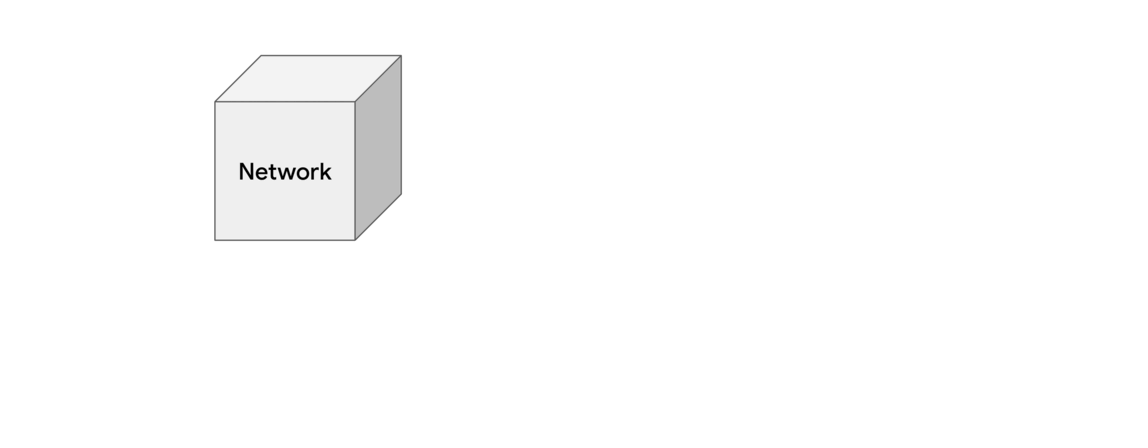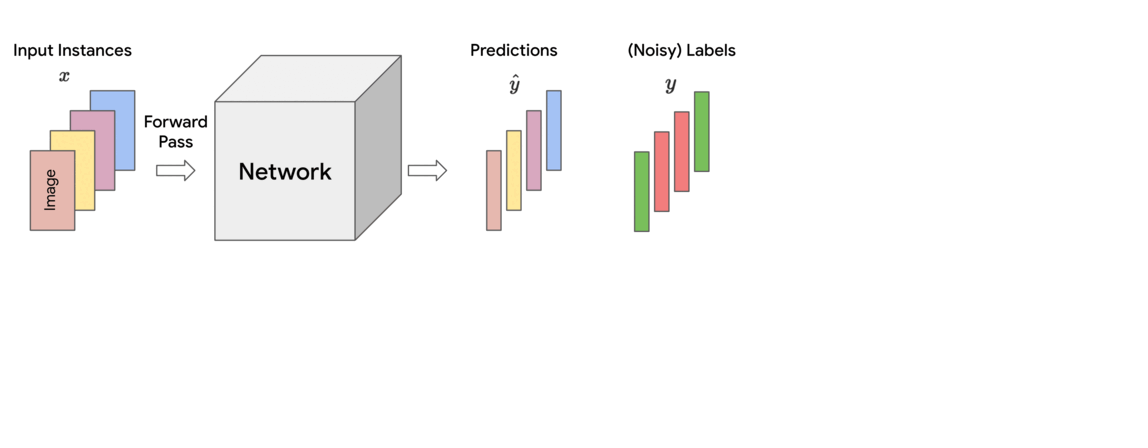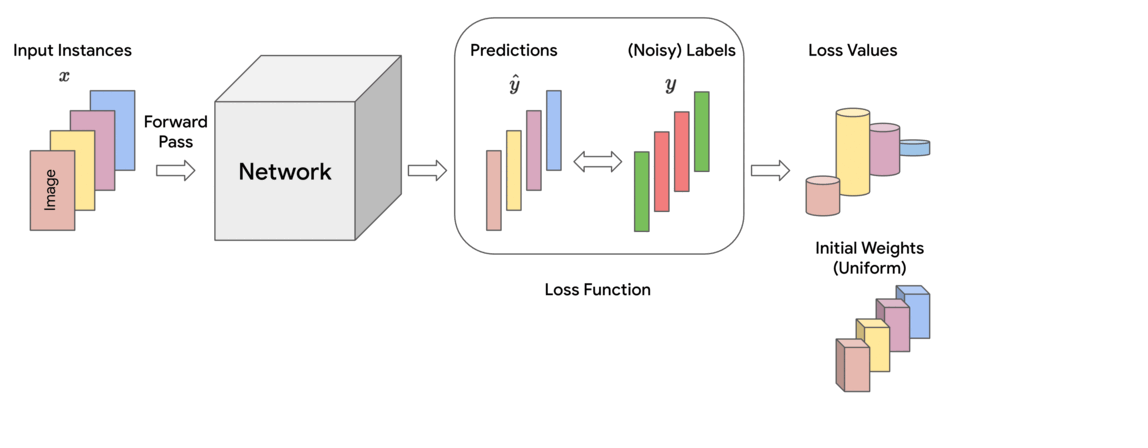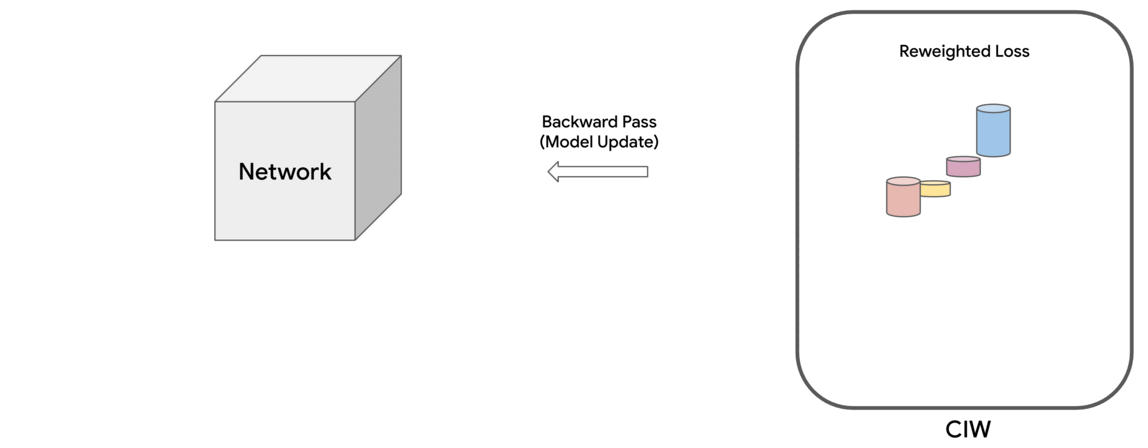 |
| Schematic of the proposed Constrained Occasion reWeighting (CIW) technique. |
Illustration with Choice Boundary on a 2D Dataset
For example as an example the conduct of this technique, we think about a loud model of the Two Moons dataset, which consists of randomly sampled factors from two courses within the form of two half moons. We corrupt 30% of the labels and prepare a multilayer perceptron community on it for binary classification. We use the usual binary cross-entropy loss and an SGD with momentum optimizer to coach the mannequin. Within the determine beneath (left panel), we present the information factors and visualize an appropriate determination boundary separating the 2 courses with a dotted line. The factors marked purple within the higher half-moon and people marked inexperienced within the decrease half-moon point out noisy information factors.
The baseline mannequin educated with the binary cross-entropy loss assigns uniform weights to the cases in every mini-batch, thus ultimately overfitting to the noisy cases and leading to a poor determination boundary (center panel within the determine beneath).
The CIW technique reweights the cases in every mini-batch primarily based on their corresponding loss values (proper panel within the determine beneath). It assigns bigger weights to the clear cases which might be positioned on the right facet of the choice boundary and damps the impact of noisy cases that incur a better loss worth. Smaller weights for noisy cases assist in stopping the mannequin from overfitting to them, thus permitting the mannequin educated with CIW to efficiently converge to determination boundary by avoiding the affect of label noise.
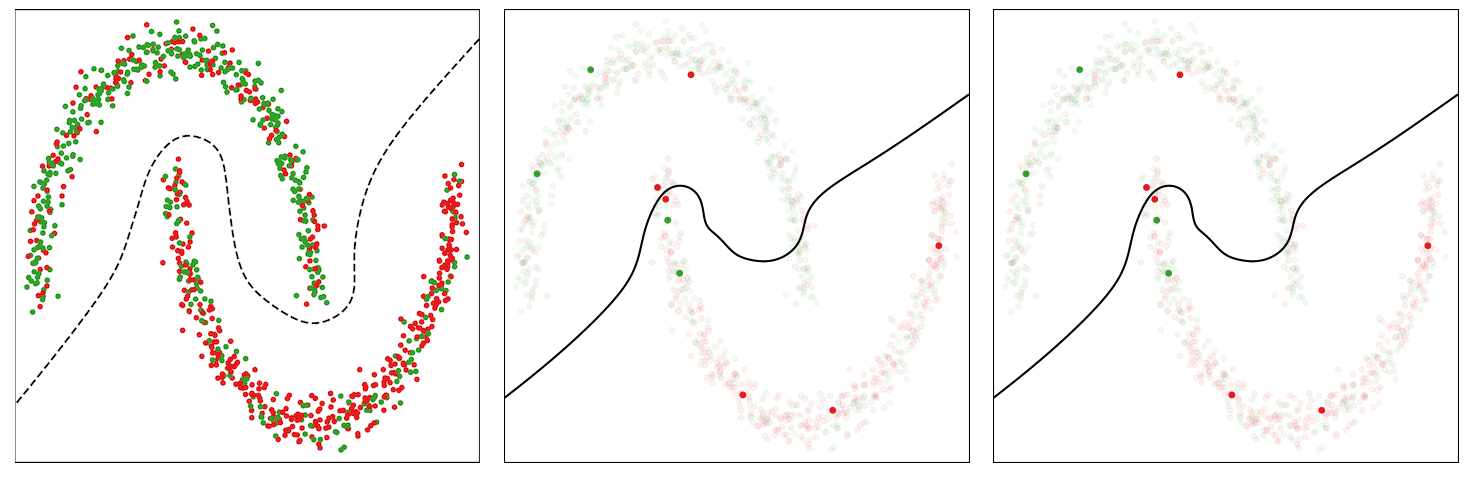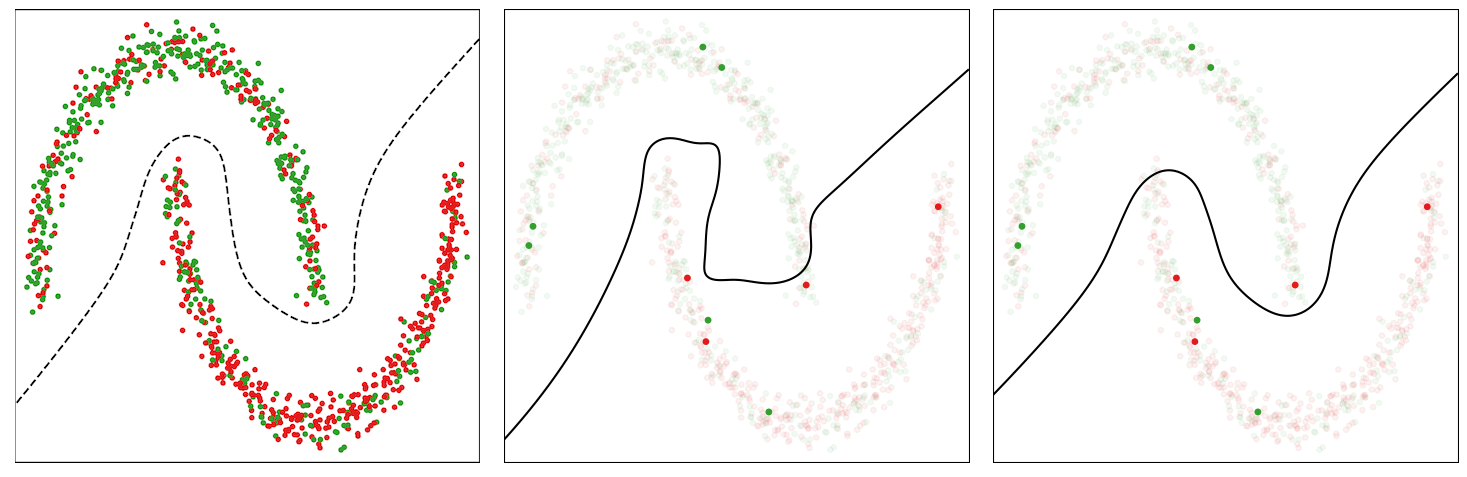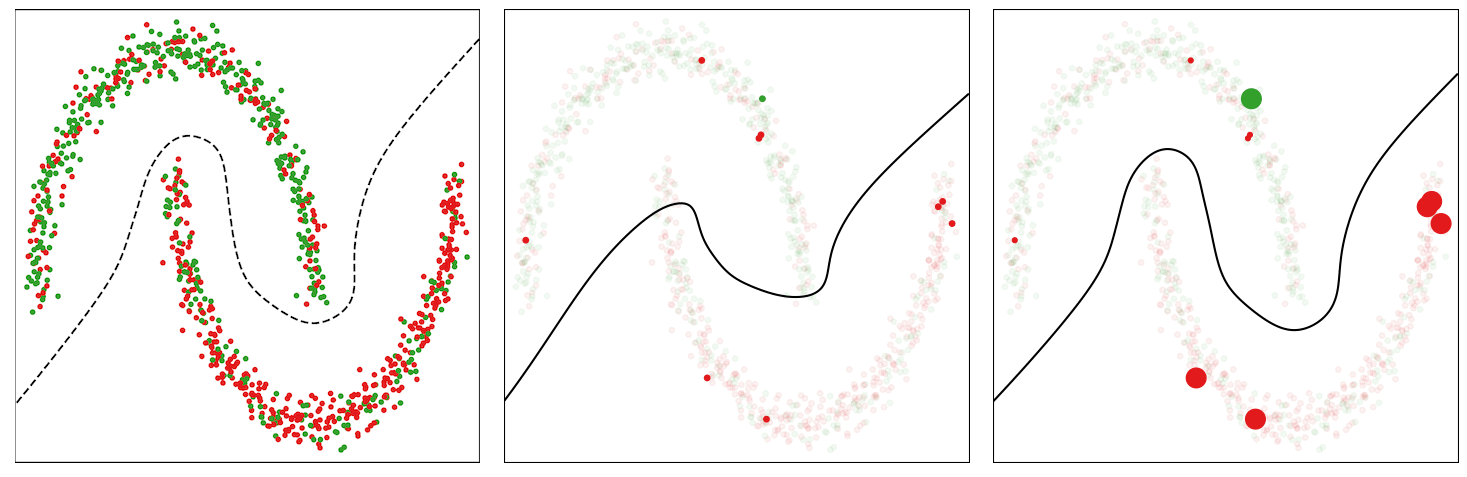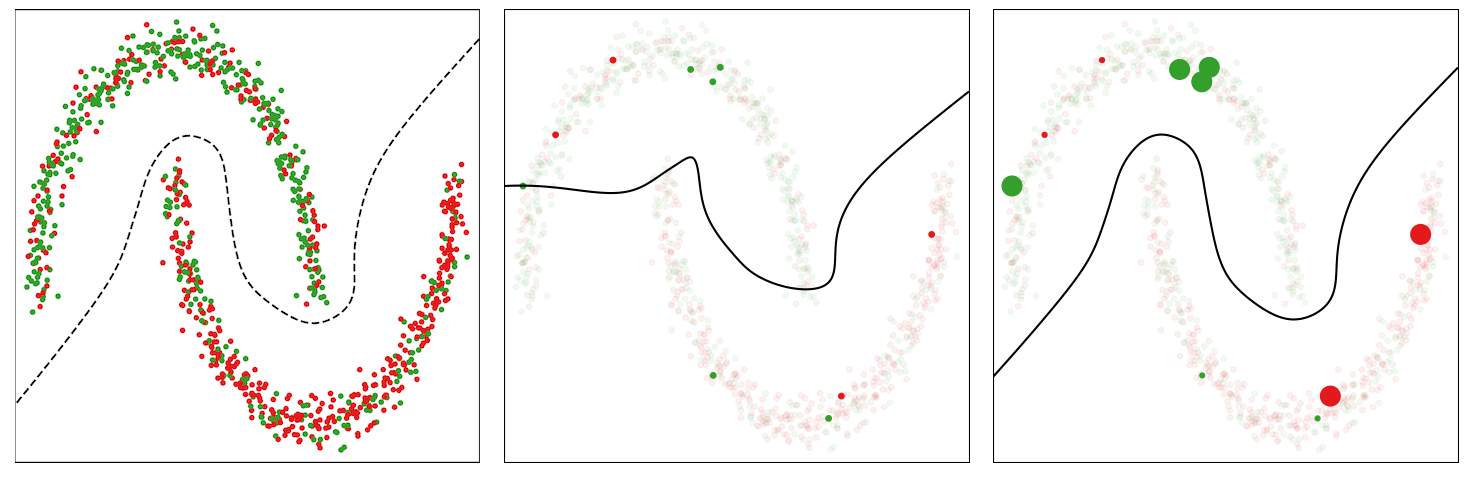 |
| Illustration of determination boundary because the coaching proceeds for the baseline and the proposed CIW technique on the Two Moons dataset. Left: Noisy dataset with a fascinating determination boundary. Center: Choice boundary for traditional coaching with cross-entropy loss. Proper: Coaching with the CIW technique. The dimensions of the dots in (center) and (proper) are proportional to the significance weights assigned to those examples within the minibatch. |
Constrained Class reWeighting
Occasion reweighting assigns decrease weights to cases with greater losses. We additional prolong this instinct to assign significance weights over all potential class labels. Customary coaching makes use of a one-hot label vector as the category weights, assigning a weight of 1 to the labeled class and 0 to all different courses. Nonetheless, for the possibly mislabeled cases, it’s affordable to assign non-zero weights to courses that could possibly be the true label. We get hold of these class weights as options to a household of constrained optimization issues the place the deviation of the category weights from the label one-hot distribution, as measured by a divergence of alternative, is managed by a hyperparameter.
Once more, for a number of divergence measures, we will get hold of easy formulae for the category weights. We discuss with this as Constrained Occasion and Class reWeighting (CICW). The answer to this optimization downside additionally recovers the earlier proposed strategies primarily based on static label bootstrapping (additionally referred as label smoothing) when the divergence is taken to be complete variation distance. This gives a theoretical perspective on the favored technique of static label bootstrapping.
Utilizing Occasion Weights with Mixup
We additionally suggest a approach to make use of the obtained occasion weights with mixup, which is a widespread technique for regularizing fashions and enhancing prediction efficiency. It really works by sampling a pair of examples from the unique dataset and producing a brand new synthetic instance utilizing a random convex mixture of those. The mannequin is educated by minimizing the loss on these mixed-up information factors. Vanilla mixup is oblivious to the person occasion losses, which is perhaps problematic for noisy information as a result of mixup will deal with clear and noisy examples equally. Since a excessive occasion weight obtained with our CIW technique is extra prone to point out a clear instance, we use our occasion weights to do a biased sampling for mixup and in addition use the weights in convex mixtures (as a substitute of random convex mixtures in vanilla mixup). This ends in biasing the mixed-up examples in direction of clear information factors, which we discuss with as CICW-Mixup.
We apply these strategies with various quantities of artificial noise (i.e., the label for every occasion is randomly flipped to different labels) on the usual CIFAR-10 and CIFAR-100 benchmark datasets. We present the check accuracy on clear information with symmetric artificial noise the place the noise charge is assorted between 0.2 and 0.8.
We observe that the proposed CICW outperforms a number of strategies and matches the outcomes of dynamic mixup, which maintains the significance weights over the complete coaching set with mixup. Utilizing our significance weights with mixup in CICW-M, resulted in considerably improved efficiency vs these strategies, significantly for bigger noise charges (as proven by traces above and to the proper within the graphs beneath).
Abstract and Future Instructions
We formulate a novel household of constrained optimization issues for tackling label noise that yield easy mathematical formulae for reweighting the coaching cases and sophistication labels. These formulations additionally present a theoretical perspective on current label smoothing–primarily based strategies for studying with noisy labels. We additionally suggest methods for utilizing the occasion weights with mixup that ends in additional important efficiency features over occasion and sophistication reweighting. Our technique operates solely on the stage of mini-batches, which avoids the additional overhead of sustaining dataset-level weights as in among the current strategies.
As a path for future work, we want to consider the strategy on sensible noisy labels which might be encountered in massive scale sensible settings. We additionally imagine that learning the interplay of our framework with label smoothing is an fascinating path that can lead to a loss adaptive model of label smoothing. We’re additionally excited to launch the code for CICW, now out there on Github.
Acknowledgements
We would prefer to thank Kevin Murphy for offering constructive suggestions through the course of the venture.
[ad_2]