Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

[ad_1]
You should utilize Apache Kafka to run your streaming workloads. Kafka supplies resiliency to failures and protects your knowledge out of the field by replicating knowledge throughout the brokers of the cluster. This makes positive that the information within the cluster is sturdy. You’ll be able to obtain your sturdiness SLAs by altering the replication issue of the subject. Nonetheless, streaming knowledge saved in Kafka matters tends to be transient and usually has a retention time of days or even weeks. You might need to again up the information saved in your Kafka matter lengthy after its retention time expires for a number of causes. For instance, you may need compliance necessities that require you to retailer the information for a number of years. Or you will have curated artificial knowledge that must be repeatedly hydrated into Kafka matters earlier than beginning your workload’s integration exams. Or an upstream system that you just don’t have management over produces dangerous knowledge and that you must restore your matter to a beforehand properly state.
Storing knowledge indefinitely in Kafka matters is an choice, however generally the use case requires a separate copy. Instruments resembling MirrorMaker allow you to again up your knowledge into one other Kafka cluster. Nonetheless, this requires one other lively Kafka cluster to be working as a backup, which will increase compute prices and storage prices. A cheap and sturdy approach of backing up the information of your Kafka cluster is to make use of an object storage service like Amazon Easy Storage Service (Amazon S3).
On this put up, we stroll via an answer that allows you to again up your knowledge for chilly storage utilizing Amazon MSK Join. We restore the backed-up knowledge to a different Kafka matter and reset the buyer offsets based mostly in your use case.
Kafka Join is a part of Apache Kafka that simplifies streaming knowledge between Kafka matters and exterior techniques like object shops, databases, and file techniques. It makes use of sink connectors to stream knowledge from Kafka matters to exterior techniques, and supply connectors to stream knowledge from exterior techniques to Kafka matters. You should utilize off-the-shelf connectors written by third events or write your individual connectors to satisfy your particular necessities.
MSK Join is a characteristic of Amazon Managed Streaming for Apache Kafka (Amazon MSK) that allows you to run totally managed Kafka Join workloads. It really works with MSK clusters and with appropriate self-managed Kafka clusters. On this put up, we use the Lenses AWS S3 Connector to again up the information saved in a subject in an Amazon MSK cluster to Amazon S3 and restore this knowledge again to a different matter. The next diagram reveals our resolution structure.

To implement this resolution, we full the next steps:
Be sure to finish the next steps as conditions:
source_topic and target_topic.Relying on the use case, chances are you’ll need to again up all of the matters in your Kafka cluster or again up some particular matters. On this put up, we cowl easy methods to again up a single matter, however you’ll be able to prolong the answer to again up a number of matters.
The format through which the information is saved in Amazon S3 is essential. You might need to examine the information that’s saved in Amazon S3 to debug points just like the introduction of dangerous knowledge. You’ll be able to study knowledge saved as JSON or plain textual content through the use of textual content editors and looking out within the time frames which are of curiosity to you. You can too study giant quantities of information saved in Amazon S3 as JSON or Parquet utilizing AWS companies like Amazon Athena. The Lenses AWS S3 Connector helps storing objects as JSON, Avro, Parquet, plaintext, or binary.
On this put up, we ship JSON knowledge to the Kafka matter and retailer it in Amazon S3. Relying on the information sort that meets your necessities, replace the join.s3.kcql assertion and *.converter configuration. You’ll be able to confer with the Lenses sink connector documentation for particulars of the codecs supported and the associated configurations. If the prevailing connectors don’t work on your use case, you too can write your individual connector or prolong current connectors. You’ll be able to partition the information saved in Amazon S3 based mostly on fields of primitive sorts within the message header or payload. We use the date fields saved within the header to partition the information on Amazon S3.
Observe these steps to again up your matter:
kcat:
MSK Join publishes metrics to Amazon CloudWatch that you should utilize to watch your backup course of. Essential metrics are SinkRecordReadRate and SinkRecordSendRate, which measure the typical variety of data learn from Kafka and written to Amazon S3, respectively.

Additionally, guarantee that the backup connector is maintaining with the speed at which the Kafka matter is receiving messages by monitoring the offset lag of the connector. When you’re utilizing Amazon MSK, you are able to do this by turning on partition-level metrics on Amazon MSK and monitoring the OffsetLag metric of all of the partitions for the backup connector’s shopper group. You need to maintain this as near 0 as potential by adjusting the utmost variety of MSK Join employee situations. The command that we used within the earlier step units MSK Connect with routinely scale as much as two employees. Modify the --capacity setting to extend or lower the utmost employee depend of MSK Join employees based mostly on the OffsetLag metric.
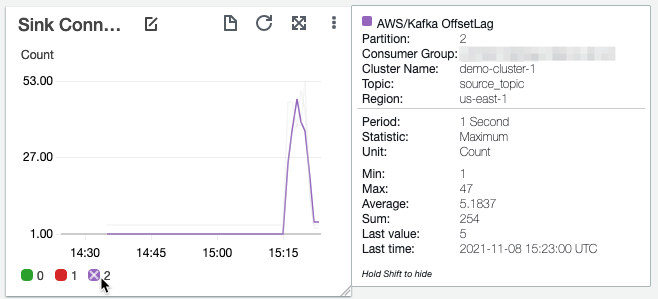
You’ll be able to restore your backed-up knowledge to a brand new matter with the identical identify in the identical Kafka cluster, a distinct matter in the identical Kafka cluster, or a distinct matter in a distinct Kafka cluster altogether. On this put up, we stroll via the state of affairs of restoring knowledge that was backed up in Amazon S3 to a distinct matter, target_topic, in the identical Kafka cluster. You’ll be able to prolong this to different situations by altering the subject and dealer particulars within the connector configuration.
Observe these steps to revive the information:
The connector reads the information from the S3 bucket and replays it again to target_topic.
MSK Join connectors run indefinitely, ready for brand new knowledge to be written to the supply. Nonetheless, whereas restoring, you need to cease the connector in spite of everything the information is copied to the subject. MSK Join publishes the SourceRecordPollRate and SourceRecordWriteRate metrics to CloudWatch, which measure the typical variety of data polled from Amazon S3 and variety of data written to the Kafka cluster, respectively. You’ll be able to monitor these metrics to trace the standing of the restore course of. When these metrics attain 0, the information from Amazon S3 is restored to the target_topic. You may get notified of the completion by organising a CloudWatch alarm on these metrics. You’ll be able to prolong the automation to invoke an AWS Lambda perform that deletes the connector when the restore is full.

As with the backup course of, you’ll be able to velocity up the restore course of by scaling out the variety of MSK Join employees. Change the --capacity parameter to regulate the utmost and minimal employees to a quantity that meets the restore SLAs of your workload.
Relying on the necessities of restoring the information to a brand new Kafka matter, you might also must reset the offsets of the shopper group earlier than consuming or producing to them. Figuring out the precise offset that you just need to reset to is determined by your particular enterprise use case and includes handbook work to establish this. You should utilize instruments like Amazon S3 Choose, Athena, or different customized instruments to examine the objects. The next screenshot demonstrates studying the data ending at offset 14 of partition 2 of matter source_topic utilizing S3 Choose.

After you establish the brand new begin offsets on your shopper teams, you need to reset them in your Kafka cluster. You are able to do this utilizing the CLI instruments that come bundled with Kafka.
If you wish to use the identical shopper group identify after restoring the subject, you are able to do this by working the next command for every partition of the restored matter:
Confirm this by working the --describe choice of the command:
If you would like your workload to create a brand new shopper group and search to customized offsets, you are able to do this by invoking the search methodology in your Kafka shopper for every partition. Alternatively, you’ll be able to create the brand new shopper group by working the next code:
Reset the offset to the specified offsets for every partition by working the next command:
To keep away from incurring ongoing expenses, full the next cleanup steps:
On this put up, we confirmed you easy methods to again up and restore Kafka matter knowledge utilizing MSK Join. You’ll be able to prolong this resolution to a number of matters and different knowledge codecs based mostly in your workload. You’ll want to check numerous situations that your workloads could face and doc the runbook for every of these situations.
For extra data, see the next assets:
 Rakshith Rao is a Senior Options Architect at AWS. He works with AWS’s strategic prospects to construct and function their key workloads on AWS.
Rakshith Rao is a Senior Options Architect at AWS. He works with AWS’s strategic prospects to construct and function their key workloads on AWS.
[ad_2]