Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

[ad_1]
Final Up to date on October 29, 2022
As we realized what a Transformer is and the way we’d prepare the Transformer mannequin, we discover that it’s a useful gizmo to make a pc perceive human language. Nonetheless, the Transformer was initially designed as a mannequin to translate one language to a different. If we repurpose it for a unique job, we’d probably must retrain the entire mannequin from scratch. Given the time it takes to coach a Transformer mannequin is gigantic, we want to have an answer that permits us to readily reuse the educated Transformer for a lot of completely different duties. BERT is such a mannequin. It’s an extension of the encoder a part of a Transformer.
On this tutorial, you’ll study what BERT is and uncover what it will possibly do.
After finishing this tutorial, you’ll know:
Let’s get began.

A short introduction to BERT
Photograph by Samet Erköseoğlu, some rights reserved.
This tutorial is split into 4 elements; they’re:
For this tutorial, we assume that you’re already acquainted with:
Within the transformer mannequin, the encoder and decoder are linked to make a seq2seq mannequin so as so that you can carry out a translation, similar to from English to German, as you noticed earlier than. Recall that the eye equation says:
$$textual content{consideration}(Q,Ok,V) = textual content{softmax}Massive(frac{QK^high}{sqrt{d_k}}Massive)V$$
However every of the $Q$, $Ok$, and $V$ above is an embedding vector reworked by a weight matrix within the transformer mannequin. Coaching a transformer mannequin means discovering these weight matrices. As soon as the burden matrices are realized, the transformer turns into a language mannequin, which implies it represents a approach to perceive the language that you simply used to coach it.

The encoder-decoder construction of the Transformer structure
Taken from “Consideration Is All You Want“
A transformer has encoder and decoder elements. Because the identify implies, the encoder transforms sentences and paragraphs into an inner format (a numerical matrix) that understands the context, whereas the decoder does the reverse. Combining the encoder and decoder permits a transformer to carry out seq2seq duties, similar to translation. If you happen to take out the encoder a part of the transformer, it will possibly inform you one thing in regards to the context, which may do one thing attention-grabbing.
The Bidirectional Encoder Illustration from Transformer (BERT) leverages the eye mannequin to get a deeper understanding of the language context. BERT is a stack of many encoder blocks. The enter textual content is separated into tokens as within the transformer mannequin, and every token will likely be reworked right into a vector on the output of BERT.
A BERT mannequin is educated utilizing the masked language mannequin (MLM) and subsequent sentence prediction (NSP) concurrently.
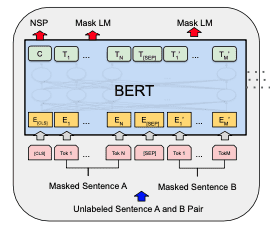
BERT mannequin
Every coaching pattern for BERT is a pair of sentences from a doc. The 2 sentences might be consecutive within the doc or not. There will likely be a [CLS] token prepended to the primary sentence (to signify the class) and a [SEP] token appended to every sentence (as a separator). Then, the 2 sentences will likely be concatenated as a sequence of tokens to develop into a coaching pattern. A small proportion of the tokens within the coaching pattern is masked with a particular token [MASK] or changed with a random token.
Earlier than it’s fed into the BERT mannequin, the tokens within the coaching pattern will likely be reworked into embedding vectors, with the positional encodings added, and explicit to BERT, with section embeddings added as effectively to mark whether or not the token is from the primary or the second sentence.
Every enter token to the BERT mannequin will produce one output vector. In a well-trained BERT mannequin, we count on:
[CLS] token initially can reveal whether or not the 2 sentences are consecutive within the docThen, the weights educated within the BERT mannequin can perceive the language context effectively.
After you have such a BERT mannequin, you need to use it for a lot of downstream duties. For instance, by including an applicable classification layer on high of an encoder and feeding in just one sentence to the mannequin as an alternative of a pair, you may take the category token [CLS] as enter for sentiment classification. It really works as a result of the output of the category token is educated to mixture the eye for the complete enter.
One other instance is to take a query as the primary sentence and the textual content (e.g., a paragraph) because the second sentence, then the output token from the second sentence can mark the place the place the reply to the query rested. It really works as a result of the output of every token reveals some details about that token within the context of the complete enter.
A transformer mannequin takes a very long time to coach from scratch. The BERT mannequin would take even longer. However the function of BERT is to create one mannequin that may be reused for a lot of completely different duties.
There are pre-trained BERT fashions that you need to use readily. Within the following, you will note a number of use circumstances. The textual content used within the following instance is from:
Theoretically, a BERT mannequin is an encoder that maps every enter token to an output vector, which might be prolonged to an infinite size sequence of tokens. In observe, there are limitations imposed within the implementation of different parts that restrict the enter dimension. Largely, a number of hundred tokens ought to work, as not each implementation can take 1000’s of tokens in a single shot. It can save you the complete article in article.txt (a duplicate is offered right here). In case your mannequin wants a smaller textual content, you need to use just a few paragraphs from it.
First, let’s discover the duty for summarization. Utilizing BERT, the thought is to extract a number of sentences from the unique textual content that signify the complete textual content. You may see this job is much like subsequent sentence prediction, during which if given a sentence and the textual content, you need to classify if they’re associated.
To try this, you’ll want to use the Python module bert-extractive-summarizer
|
pip set up bert-extractive-summarizer |
It’s a wrapper to some Hugging Face fashions to offer the summarization job pipeline. Hugging Face is a platform that permits you to publish machine studying fashions, primarily on NLP duties.
After you have put in bert-extractive-summarizer, producing a abstract is just some strains of code:
|
from summarizer import Summarizer textual content = open(“article.txt”).learn() mannequin = Summarizer(‘distilbert-base-uncased’) consequence = mannequin(textual content, num_sentences=3) print(consequence) |
This offers the output:
|
Amid the political turmoil of outgoing British Prime Minister Liz Truss’s short-lived authorities, the Financial institution of England has discovered itself within the fiscal-financial crossfire. No matter authorities comes subsequent, it’s vital that the BOE learns the precise classes. In keeping with a press release by the BOE’s Deputy Governor for Monetary Stability, Jon Cunliffe, the MPC was merely “knowledgeable of the points within the gilt market and briefed prematurely of the operation, together with its financial-stability rationale and the short-term and focused nature of the purchases.” |
That’s the whole code! Behind the scene, spaCy was used on some preprocessing, and Hugging Face was used to launch the mannequin. The mannequin used was named distilbert-base-uncased. DistilBERT is a simplified BERT mannequin that may run quicker and use much less reminiscence. The mannequin is an “uncased” one, which implies the uppercase or lowercase within the enter textual content is taken into account the identical as soon as it’s reworked into embedding vectors.
The output from the summarizer mannequin is a string. As you specified num_sentences=3 in invoking the mannequin, the abstract is three chosen sentences from the textual content. This method is named the extractive abstract. The choice is an abstractive abstract, during which the abstract is generated reasonably than extracted from the textual content. This would want a unique mannequin than BERT.
The opposite instance of utilizing BERT is to match inquiries to solutions. You’ll give each the query and the textual content to the mannequin and search for the output of the start and the top of the reply from the textual content.
A fast instance can be just some strains of code as follows, reusing the identical instance textual content as within the earlier instance:
|
from transformers import pipeline textual content = open(“article.txt”).learn() query = “What’s BOE doing?”
answering = pipeline(“question-answering”, mannequin=‘distilbert-base-uncased-distilled-squad’) consequence = answering(query=query, context=textual content) print(consequence) |
Right here, Hugging Face is used instantly. If in case you have put in the module used within the earlier instance, the Hugging Face Python module is a dependence that you simply already put in. In any other case, it’s possible you’ll want to put in it with pip:
And to truly use a Hugging Face mannequin, it’s best to have each PyTorch and TensorFlow put in as effectively:
|
pip set up torch tensorflow |
The output of the code above is a Python dictionary, as follows:
|
{‘rating’: 0.42369240522384644, ‘begin’: 1261, ‘finish’: 1344, ‘reply’: ‘to keep up or restore market liquidity in systemically importantnfinancial markets’} |
That is the place you will discover the reply (which is a sentence from the enter textual content), in addition to the start and finish place within the token order the place this reply was from. The rating might be thought to be the arrogance rating from the mannequin that the reply might match the query.
Behind the scenes, what the mannequin did was generate a likelihood rating for one of the best starting within the textual content that solutions the query, in addition to the textual content for one of the best ending. Then the reply is extracted by discovering the placement of the best possibilities.
This part supplies extra assets on the subject if you’re trying to go deeper.
On this tutorial, you found what BERT is and the best way to use a pre-trained BERT mannequin.
Particularly, you realized:
[ad_2]