Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

[ad_1]
Now we have all grow to be spoiled by engines like google’ skill to “workaround” issues like spelling errors, identify spelling variations, or every other state of affairs the place the search time period might match on pages whose authors might favor to make use of a distinct spelling of a phrase. Including such options to our personal database-driven functions can equally enrich and improve our functions, and whereas business relational database administration methods (RDBMS) choices present their very own absolutely developed personalized options to this downside, the licensing prices of those instruments may be out of attain for smaller builders or small software program improvement companies.
One may argue that this might be carried out utilizing a spell checker as a substitute. Nevertheless, a spell checker is often of no use when matching an accurate, however different, spelling of a reputation or different phrase. Matching by sound fills this practical hole. That’s the subject of at present’s programming tutorial: how one can question sounds with Python utilizing Metaphones.
Learn: Picture Recognition in Python
Soundex was developed within the early twentieth century as a method for the US Census to match names based mostly on how they sound. It was then utilized by varied cellphone firms to match buyer names. It continues for use for phonetic knowledge matching to this present day regardless of it being restricted to American English spellings and pronunciations. It’s also restricted to English letters. Most RDBMS, comparable to SQL Server and Oracle, together with MySQL and its variants, implement a Soundex perform and, regardless of its limitations, it continues for use to match many non-English phrases.
The Metaphone algorithm was developed in 1990 and it overcomes a few of the limitations of Soundex. In 2000, an improved follow-on, Double Metaphone, was developed. Double Metaphone returns a major and secondary worth which corresponds to 2 methods a single phrase might be pronounced. To this present day this algorithm stays one of many higher open-source phonetic algorithms. Metaphone 3 was launched in 2009 as an enchancment to Double Metaphone, however this can be a business product.
Sadly, lots of the outstanding RDBMS talked about above doesn’t implement Double Metaphone, and most outstanding scripting languages don’t present a supported implementation of Double Metaphone. Nevertheless, Python does present a module that implements Double Metaphone.
The examples introduced on this Python programming tutorial use MariaDB model 10.5.12 and Python 3.9.2, each working on Kali/Debian Linux.
Learn: How you can Create Your First Python GUI Software
Like all Python module, the pip device can be utilized to put in Double Metaphone. The syntax relies on your Python set up. A typical Double Metaphone set up seems to be like the next instance:
# Typical in case you have solely Python 3 put in $ pip set up doublemetaphone # In case your system has Python 2 and Python 3 put in $ /usr/bin/pip3 set up DoubleMetaphone
Word, that the additional capitalization is intentional. The next code is an instance of how one can use Double Metaphone in Python:
# demo.py
import sys
# pip set up doublemetaphone
# /usr/bin/pip3 set up DoubleMetaphone
from doublemetaphone import doublemetaphone
def essential(argv):
testwords = ["There", "Their", "They're", "George", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt"]
for testword in testwords:
print (testword + " - ", finish="")
print (doublemetaphone(testword))
return 0
if __name__ == "__main__":
essential(sys.argv[1:])
Itemizing 1 - Demo script to confirm performance
The above Python script offers the next output when run in your built-in improvement surroundings (IDE) or code editor:
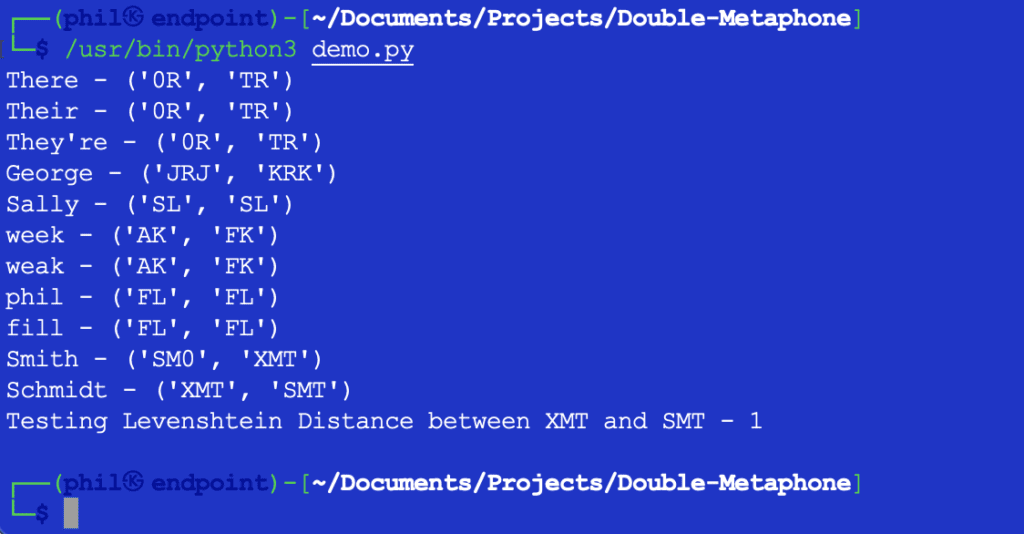
Determine 1 – Output of Demo Script
As may be seen right here, every phrase has each a major and secondary phonetic worth. Phrases that match on each major or secondary values are mentioned to be phonetic matches. Phrases that share at the least one phonetic worth, or which share the primary couple of characters in any phonetic worth, are mentioned to be phonetically close to to 1 one other.
Most letters displayed correspond to their English pronunciations. X can correspond to KS, SH, or C. 0 corresponds to the th sound in the or there. Vowels are solely matched at the start of a phrase. Due to the uncountable variety of variations in regional accents, it’s not doable to say that phrases may be an objectively precise match, even when they’ve the identical phonetic values.
There are quite a few on-line assets that may describe the complete workings of the Double Metaphone algorithm; nonetheless, this isn’t needed with a view to use it as a result of we’re extra keen on evaluating the calculated values, greater than we’re keen on calculating the values. As said earlier, if there’s at the least one worth in widespread between two phrases, it may be mentioned that these values are phonetic matches, and phonetic values which are related are phonetically shut.
Evaluating absolute values is straightforward, however how can strings be decided to be related? Whereas there aren’t any technical limitations that cease you from evaluating multi-word strings, these comparisons are often unreliable. Keep on with evaluating single phrases.
Learn: Textual content Scraping in Python
The Levenshtein Distance between two strings is the variety of single characters that should be modified in a single string with a view to make it match the second string. A pair of strings which have a decrease Levenshtein distance are extra related to one another than a pair of strings which have the next Levenshtein distance. Levenshtein Distance is just like Hamming Distance, however the latter is proscribed to strings of the identical size, because the Double Metaphone phonetic values can fluctuate in size, it makes extra sense to check these utilizing the Levenshtein Distance.
Python may be prolonged to assist Levenshtein Distance calculations by way of a Python Module:
# In case your system has Python 2 and Python 3 put in $ /usr/bin/pip3 set up python-Levenshtein
Word that, as with the set up of the DoubleMetaphone above, the syntax of the decision to pip might fluctuate. The python-Levenshtein module offers much more performance than simply calculations of Levenshtein Distance.
The code beneath reveals a check for Levenshtein Distance calculation in Python:
# demo.py
import sys
# pip set up doublemetaphone
# /usr/bin/pip3 set up DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 set up python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
def essential(argv):
testwords = ["There", "Their", "They're", "George", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt"]
for testword in testwords:
print (testword + " - ", finish="")
print (doublemetaphone(testword))
print ("Testing Levenshtein Distance between XMT and SMT - " + str(distance('XMT', 'SMT')))
return 0
if __name__ == "__main__":
essential(sys.argv[1:])
Itemizing 2 - Demo prolonged to confirm Levenshtein Distance calculation performance
Executing this script offers the next output:

Determine 2 – Output of Levenshtein Distance check
The returned worth of 1 signifies that there’s one character between XMT and SMT that’s totally different. On this case, it’s the first character in each strings.
What follows shouldn’t be the be-all-and-end-all of phonetic comparisons. It’s merely certainly one of some ways to carry out such a comparability. To successfully examine the phonetic nearness of any two given strings, then every Double Metaphone phonetic worth of 1 string should be in comparison with the corresponding Double Metaphone phonetic worth of one other string. Since each phonetic values of a given string are given equal weight, then the common of those comparability values will give a fairly good approximation of phonetic nearness:
PN = [ Dist(DM11, DM21,) + Dist(DM12, DM22,) ] / 2.0
The place:
This components breaks down in instances like Schmidt (XMT, SMT) and Smith (SM0, XMT) the place the primary phonetic worth of the primary string matches the second phonetic worth of the second string. In such conditions, each Schmidt and Smith may be thought of to be phonetically related due to the shared worth. The code for the nearness perform ought to apply the components above solely when all 4 phonetic values are totally different. The components additionally has weaknesses when evaluating strings of differing lengths.
Word, there isn’t a singularly efficient method to examine strings of differing lengths, despite the fact that calculating the Levenshtein Distance between two strings components in variations in string size. A doable workaround could be to check each strings as much as the size of the shorter of the 2 strings.
Under is an instance code snippet that implements the code above, together with some check samples:
# demo2.py
import sys
# pip set up doublemetaphone
# /usr/bin/pip3 set up DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 set up python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def essential(argv):
testwords = ["Philippe", "Phillip", "Sallie", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt", "Harold", "Herald"]
for testword in testwords:
print (testword + " - ", finish="")
print (doublemetaphone(testword))
print ("Testing Levenshtein Distance between XMT and SMT - " + str(distance('XMT', 'SMT')))
print ("Distance between AK and AK - " + str(distance('AK', 'AK')) + "]")
print ("Evaluating week and weak - [" + str(Nearness("week", "weak")) + "]")
print ("Evaluating Harold and Herald - [" + str(Nearness("Harold", "Herald")) + "]")
print ("Evaluating Smith and Schmidt - [" + str(Nearness("Smith", "Schmidt")) + "]")
print ("Evaluating Philippe and Phillip - [" + str(Nearness("Philippe", "Phillip")) + "]")
print ("Evaluating Phil and Phillip - [" + str(Nearness("Phil", "Phillip")) + "]")
print ("Evaluating Robert and Joseph - [" + str(Nearness("Robert", "Joseph")) + "]")
print ("Evaluating Samuel and Elizabeth - [" + str(Nearness("Samuel", "Elizabeth")) + "]")
return 0
if __name__ == "__main__":
essential(sys.argv[1:])
Itemizing 3 - Implementation of the Nearness Algorithm Above
The pattern Python code offers the next output:
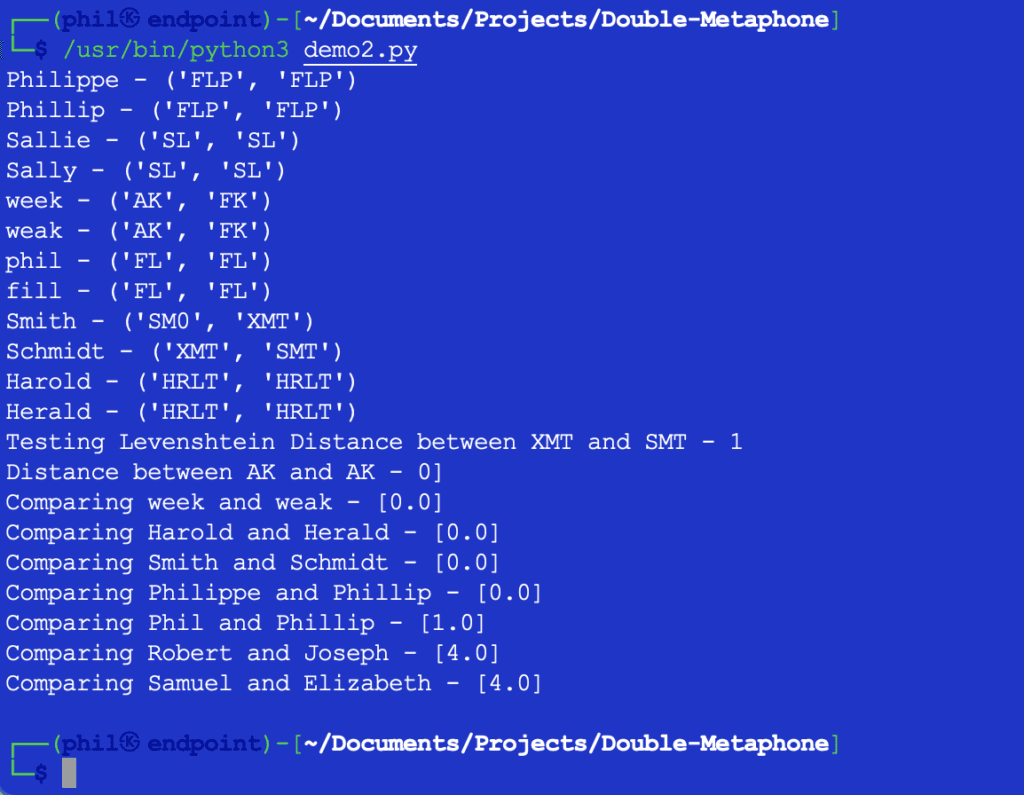
Determine 3 – Output of the Nearness Algorithm
The pattern set confirms the overall development that the higher the variations in phrases, the upper the output of the Nearness perform.
Learn: File Dealing with in Python
The code above breaches the practical hole between a given RDBMS and a Double Metaphone implementation. On prime of this, by implementing the Nearness perform in Python, it turns into straightforward to switch ought to a distinct comparability algorithm be most popular.
Contemplate the next MySQL/MariaDB desk:
create desk demo_names (record_id int not null auto_increment, lastname varchar(100) not null default '', firstname varchar(100) not null default '', major key(record_id)); Itemizing 4 - MySQL/MariaDB CREATE TABLE assertion
In most database-driven functions, the middleware composes SQL Statements for managing the information, together with inserting it. The next code will insert some pattern names into this desk, however in apply, any code from an internet or desktop utility which collects such knowledge may do the identical factor.
# demo3.py
import sys
# pip set up doublemetaphone
# /usr/bin/pip3 set up DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 set up python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
# /usr/bin/pip3 set up mysql.connector
import mysql.connector
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def essential(argv):
testNames = ["Smith, Jane", "Williams, Tim", "Adams, Richard", "Franks, Gertrude", "Smythe, Kim", "Daniels, Imogen", "Nguyen, Nancy",
"Lopez, Regina", "Garcia, Roger", "Diaz, Catalina"]
mydb = mysql.connector.join(
host="localhost",
person="sound_demo_user",
password="password1",
database="sound_query_demo")
for identify in testNames:
nameParts = identify.break up(',')
# Usually one ought to do bounds checking right here.
firstname = nameParts[1].strip()
lastname = nameParts[0].strip()
sql = "insert into demo_names (lastname, firstname) values(%s, %s)"
values = (lastname, firstname)
insertCursor = mydb.cursor()
insertCursor.execute (sql, values)
mydb.commit()
mydb.shut()
return 0
if __name__ == "__main__":
essential(sys.argv[1:])
Itemizing 5 - Inserting pattern knowledge right into a database.
Operating this code doesn’t print something, however it does populate the testing desk within the database for the subsequent itemizing to make use of. Querying the desk instantly within the MySQL shopper can confirm that the code above labored:
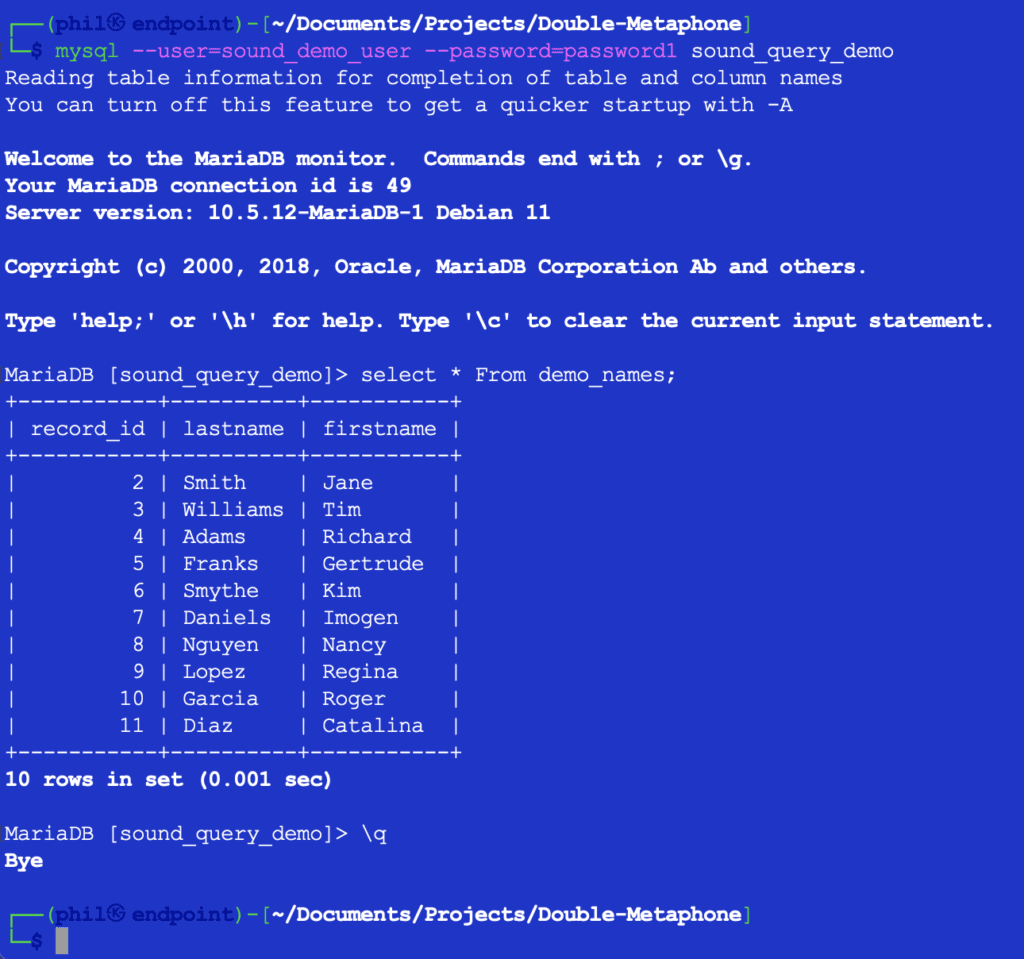
Determine 4- The Inserted Desk Information
The code beneath will feed some comparability knowledge into the desk knowledge above and carry out a nearness comparability towards it:
# demo4.py
import sys
# pip set up doublemetaphone
# /usr/bin/pip3 set up DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 set up python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
# /usr/bin/pip3 set up mysql.connector
import mysql.connector
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def essential(argv):
comparisonNames = ["Smith, John", "Willard, Tim", "Adamo, Franklin" ]
mydb = mysql.connector.join(
host="localhost",
person="sound_demo_user",
password="password1",
database="sound_query_demo")
sql = "choose lastname, firstname from demo_names order by lastname, firstname"
cursor1 = mydb.cursor()
cursor1.execute (sql)
results1 = cursor1.fetchall()
cursor1.shut()
mydb.shut()
for comparisonName in comparisonNames:
nameParts = comparisonName.break up(",")
firstname = nameParts[1].strip()
lastname = nameParts[0].strip()
print ("Comparability for " + firstname + " " + lastname + ":")
for lead to results1:
firstnameNearness = Nearness (firstname, consequence[1])
lastnameNearness = Nearness (lastname, consequence[0])
print ("t[" + firstname + "] vs [" + result[1] + "] - " + str(firstnameNearness)
+ ", [" + lastname + "] vs [" + result[0] + "] - " + str(lastnameNearness))
return 0
if __name__ == "__main__":
essential(sys.argv[1:])
Itemizing 5 - Nearness Comparability Demo
Operating this code will get us the output beneath:
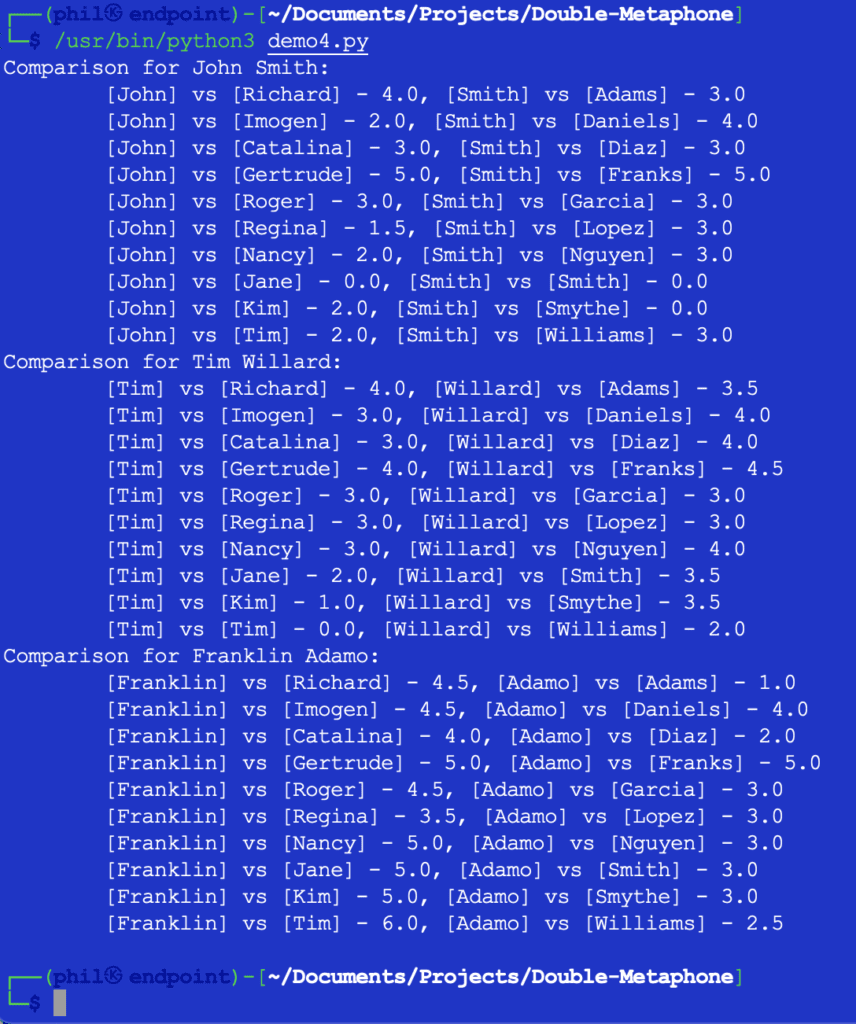
Determine 5 – Outcomes of the Nearness Comparability
At this level, it might be as much as the developer to determine what the edge could be for what constitutes a helpful comparability. Among the numbers above could appear sudden or stunning, however one doable addition to the code is perhaps an IF assertion to filter out any comparability worth that’s higher than 2.
It could be price noting that the phonetic values themselves usually are not saved within the database. It’s because they’re calculated as a part of the Python code and there’s not an actual must retailer these anyplace as they’re discarded when this system exits, nonetheless, a developer might discover worth in storing these within the database after which implementing the comparability perform throughout the database a saved process. Nevertheless, the one main draw back of this can be a lack of code portability.
Learn: Prime On-line Programs to Study Python
Evaluating knowledge by sound doesn’t appear to get the “love” or consideration that evaluating a knowledge by picture evaluation might get, but when an utility has to take care of a number of similar-sounding variants of phrases in a number of languages, it may be a crucially useful gizmo. One helpful characteristic of any such evaluation is {that a} developer needn’t be a linguistics or phonetic professional with a view to make use of those instruments. The developer additionally has nice flexibility in defining how such knowledge may be in contrast; the comparisons may be tweaked based mostly on the applying or enterprise logic wants.
Hopefully, this discipline of research will get extra consideration within the analysis sphere and there shall be extra succesful and sturdy evaluation instruments going ahead.
Learn extra Python programming and software program improvement tutorials.
[ad_2]